October 9, 2019
How Digital Transformation Enables Big Data Analytics
A cloud data warehouse is a database delivered in a public cloud as a managed service that is optimized for analytics, scale and ease of use.
In the late 80s, I remember my first time working with Oracle 6, a “relational” database where data was formatted into tables. The concept of a data service where I could load data and then query it with a standard language (SQL) was a game changer for me. In the 90s, when relational databases began to struggle with the size and complexity of analytical workloads, we saw the emergence of the MPP data warehouses like Teradata, Netezza and later, Vertica and Greenplum. In 2010 at Yahoo!, more than 20 years after the birth of the relational database, I was lucky enough to witness a sea change in data management with an open source project called Hadoop. The concept of a “data lake” where I could query raw unstructured data was a huge leap forward in my ability to capture, store and process more data with more agility at a substantially lower cost.
We’re now witnessing a third wave of innovation in data warehousing technology with the advent of cloud data warehouses. As enterprises move to the cloud, they are abandoning their legacy on-premise data warehousing technologies, including Hadoop, for these new cloud data platforms. This transformation is a huge tectonic shift in data management and has profound implications for enterprises.
The Benefits of a Cloud Data Warehouse
Cloud-based data warehouses free up companies to focus on running their business, rather than running a room full of servers, and they allow business intelligence teams to deliver faster and better insights due to improved access, scalability, and performance.
- Data Access: Putting their data in the cloud enables companies to give their analysts access to real-time data from numerous sources, allowing them to run better analytics quickly.
- Scalability: It is much faster and less expensive to scale a cloud data warehouse than an on-premise system because it doesn’t require purchasing new hardware (and possibly over- or under-provisioning) and the scaling can happen automatically as needed
- Performance: A cloud data warehouse allows for queries to be run much more quickly than they are against a traditional on-premises data warehouse, for lower cost.
Cloud Data Warehouse Capabilities
Each of the major public cloud vendors offer their own flavor of a cloud data warehouse service: Google offers BigQuery, Amazon has Redshift and Microsoft has Azure SQL Data Warehouse. There are also cloud offerings from the likes of Snowflake that provide the same capabilities via a service that runs on the public cloud but is managed independently. For each of these services, the cloud vendor or data warehouse provider delivers the following capabilities “out of the box”:
- Data storage and management: data is stored in a cloud-based file system (i.e. S3).
- Automatic upgrades: there’s no concept of a “version” or software upgrade.
- Capacity management: it’s easy to expand (or contract) your data footprint.
Factors to Consider When Choosing a Cloud Data Warehouse
How these cloud data warehouse vendors deliver these capabilities and how they charge for them is where things get more nuanced. Let’s dive deeper into the different deployment implementations and pricing models.
Cloud Architecture: Cluster versus Serverless
There are two main camps of cloud data warehouse architectures. The first, older deployment architecture is cluster-based: Amazon Redshift and Azure SQL Data Warehouse fall into this category. Typically, clustered cloud data warehouses are really just clustered Postgres derivatives, ported to run as a service in the cloud. The other flavor, serverless, is more modern and counts Google BigQuery and Snowflake as examples. Essentially, serverless cloud data warehouses make the database cluster “invisible” or shared across many clients. Each architecture has their pros and cons (see below).
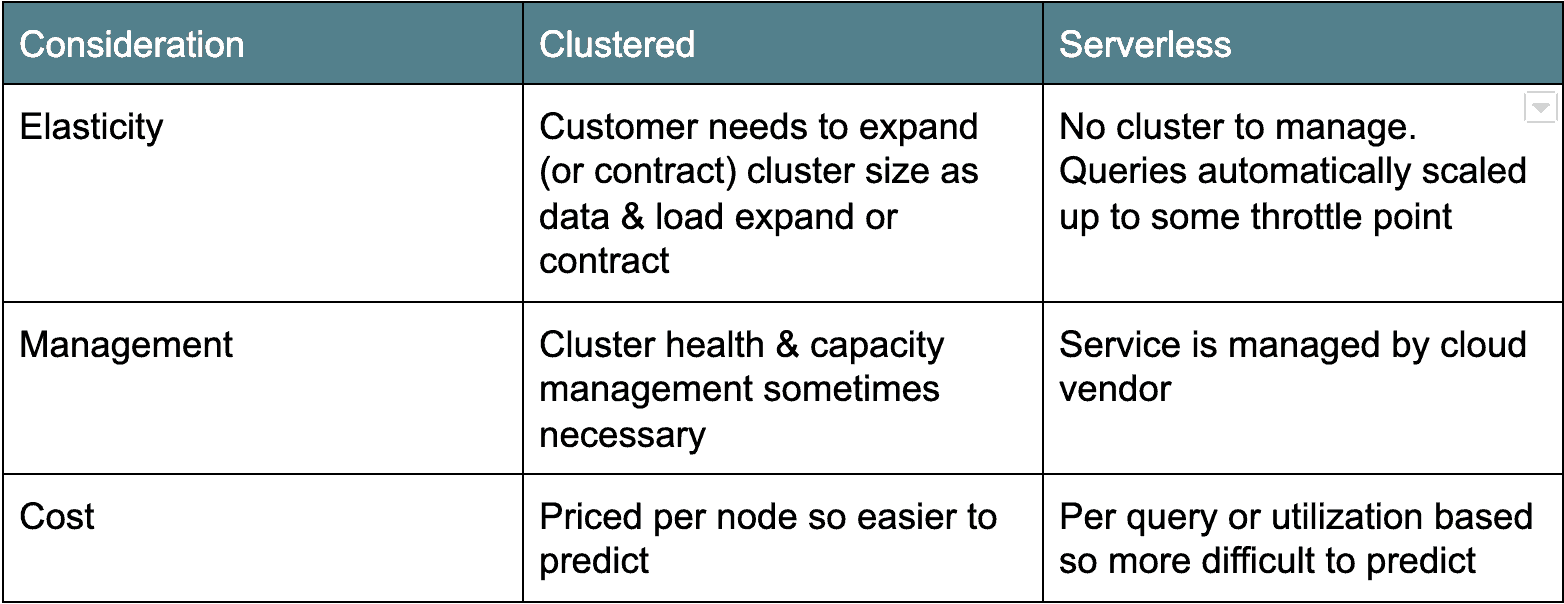
Cloud Data Pricing: Pay by the Drink or by the Server
Besides deployment architecture, another major difference between the cloud data warehouse options is pricing. In all cases, you pay some nominal fee for the amount of data stored. But the pricing differs for compute.
For example, Google BigQuery and Snowflake offer on-demand pricing options based on the amount of data scanned or compute time used. Amazon Redshift and Azure SQL Data Warehouse offer resource pricing based on the number or types of nodes in the cluster. There are pros and cons to both types of pricing models. The on-demand models only charge you for what you use which can make budgeting difficult as it is hard to predict the number of users and the number and size of the queries they will be running. I know one customer example where a user mistakenly ran a $1,000+ query.
For the node based models (i.e. Amazon Redshift and Azure SQL Data Warehouse), you pay by the server and/or server type. This pricing model is obviously more predictable but it’s “always on” so you are paying a flat price regardless of usage.
Pricing is a major consideration and requires a great deal of use case and workload modeling to find the right fit for your organization.
Challenges and Considerations for Cloud Migration (the “Gotchas”)
At AtScale, we’ve seen lots of enterprises attempt a migration from their on-premise data lakes and/or relational data warehouses to the cloud. For many, their migrations “stall” after the first pilot project due to the following reasons:
- Disruption: downstream users (business analysts, data scientists) have to change their habits and re-tool their reports and dashboards.
- Performance: the cloud DW doesn’t match performance of highly tuned, legacy on-premise data platforms.
- Sticker shock – unanticipated or unplanned operating costs and lack of cost controls.
This is where AtScale can help
Keep What you Have
AtScale A3 minimizes or eliminates business disruption due to platform migrations by allowing the business to continue to use their existing BI tools, dashboards and reports without re-coding or abandoning them altogether. How can we do this? The AtScale Universal Semantic Layer™ provides an abstraction that leverages your legacy platform schemas by virtually re-mapping them to your new cloud data warehouse. This means your existing reports and dashboards will work on the new cloud data platform with minimal or no re-coding.
Supercharge your Performance
I see many enterprises become disillusioned with the performance of their new cloud data platform. What they often fail to consider is that their existing on-premise data warehouse (i.e. Teradata, Oracle) have been tuned for years or even decades. Getting the same level of performance “out of the box” with a cloud data warehouse is not realistic.
The AtScale Adaptive Cache™ works by automatically generating aggregates on your cloud data platform based on user query patterns. By avoiding costly and time consuming table scans, the AtScale platform delivers fast, consistent queries at “speed of thought”. We’ve helped many customers get past their performance challenges and unblock their cloud migrations.
Keep a Lid on Costs
I can’t even count the number of times I’ve heard IT folks complain that their cloud costs are much higher than they anticipated and unpredictable to boot. Again, it the AtScale Adaptive Cache™ to the rescue. By reducing unnecessary table scans, we can improve overall performance, concurrency, and cost predictability, allowing you to get more out of your data platform without increasing the cost. With AtScale’s machine generated queries, we will make your costs predictable and eliminate the risk associated with hand-written SQL queries.
I sincerely believe that cloud data warehouses are a game changer and the next wave in data warehousing. Used thoughtfully, cloud data warehouses can dramatically lower your operating costs while giving you the agility to keep up with the demands of the business.
NEW BOOK