July 11, 2019
DATA VIRTUALIZATION VS. DATA WAREHOUSE
According to Gartner, “By 2022, 60% of all organizations will implement data virtualization as one key delivery style in their data integration architecture.” Recently, AtScale, Cloudera and ODPI.org collaborated on a survey to learn about the maturity of the Big Data & Analytics marketplace and discovered similar results. Our survey showed that 47 of our 150 respondents are using data virtualization now and 57 respondents plan to use data virtualization in the future.
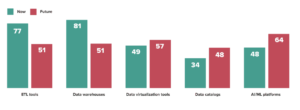
Data virtualization technology has been around for quite some time. However, the explosion in data size and variety, coupled with the increased focus on analytical use cases, has created new challenges for legacy data virtualization technologies. The need for ad hoc access to both live and historical data has steadily increased among business users as they leverage artificial intelligence (AI) and machine learning (ML) platforms for analytics.
In The Complete Buyer’s Guide for Intelligent Data Virtualization, AtScale’s co-founder and chief strategy officer, Dave Mariani, writes that “It wasn’t that long ago when most data consumers believed that a centralized data warehouse could be the data panacea for the enterprise. It didn’t take long to realize that the demands of the business were too fluid to wait on IT to collect, normalize and store data in a single physical location. The explosion of data sizes, varieties and formats have made it all but impossible to standardize on a single storage format. Even worse, with the emerging popularity of the public cloud, data stewards now need to deal with data locales as well. While it’s tough enough for those who need to engineer and secure the data, it’s even harder for the consumers of data. We are now asking our business users to engineer, wrangle and access data on-premise, in the cloud, in databases and in data lakes.”
Sound familiar? Data is becoming more diverse than it ever has been before. With poor decision making resulting from long manual processes, conflicting answers becoming the solution to the same questions, and the risk of your data residing in insecure environments; it’s clear that you need to consolidate and make your life simpler. Enter intelligent data virtualization.
What is Intelligent Data Virtualization?
Intelligent Data Virtualization pulls together all of your data from wherever it is stored into a single, logical view and delivers faster time to analysis by removing manual data engineering required to physically move data to one place. Intelligent Data Virtualization breaks down the complexity of how and where your data is stored so you can easily query your data in a single, consistent and governed logical view.
How AtScale Can Help with Intelligent Data Virtualization

Intelligent Data Virtualization platforms avoid high volumes of real-time data traffic to deliver more consistent query performance with far less resource consumption. Using AtScale Adaptive Analytics, an intelligent data virtualization solution, you can simplify your data access for your BI and AI users. Using a single virtual cube to create a singular view of your data, you can leave the data where it is, whether that be on-premise or in the cloud without interfering with your current workflow.
To learn how to unlock the true power of your data, take a look at these resources on Intelligent Data Virtualization:
- Read the Digital Transformation Arrives with Next-Gen Intelligent Data Virtualization blog article
- Download the Data Virtualization and Data Architecture Modernization whitepaper
- Take a look at: The Ultimate Data Virtualization Buyer’s Checklist
NEW BOOK