
In recent years, enterprise organizations have opted to migrate to or establish data lakes on cloud technologies to lower costs and increase performance. Cloud solutions’ pay-per-use pricing model and ability to scale on-demand, enables organizations to effectively analyze large data sets at a lower cost than if that data was stored in traditional on-premise solutions. Amazon Web Services’ ability to accommodate expanding large-scale data volumes and to process structured and unstructured data formats in the same environment, make the AWS ecosystem of technologies a highly popular set of solutions to address common data challenges.
The AWS ecosystem includes Amazon S3 and Amazon Redshift for storing and collecting data, and Amazon EMR to process data. BI tools such as Excel, Tableau, and Power BI are commonly used to pull data from S3 and Redshift. Like other cloud providers, AWS employs a pay-per-use pricing model that enables the user to pay for only the services used without requiring contracts or deposits. However, an important element to note about the cost of AWS is that the pricing for Redshift and S3 differ slightly from one another.
Amazon Redshift pricing is based on the amount of data stored and the number of nodes in use. The number of nodes can be expanded or reduced depending on the amount of data that users need to store or manage. Based on the volume of data, users can pick a setup anywhere from a single node measuring 160GB (0.016TB), to a 128 node cluster with a capacity of 16TB. This range of nodes results in a price range of anywhere from $0.25/Hr to $6.80/Hr.
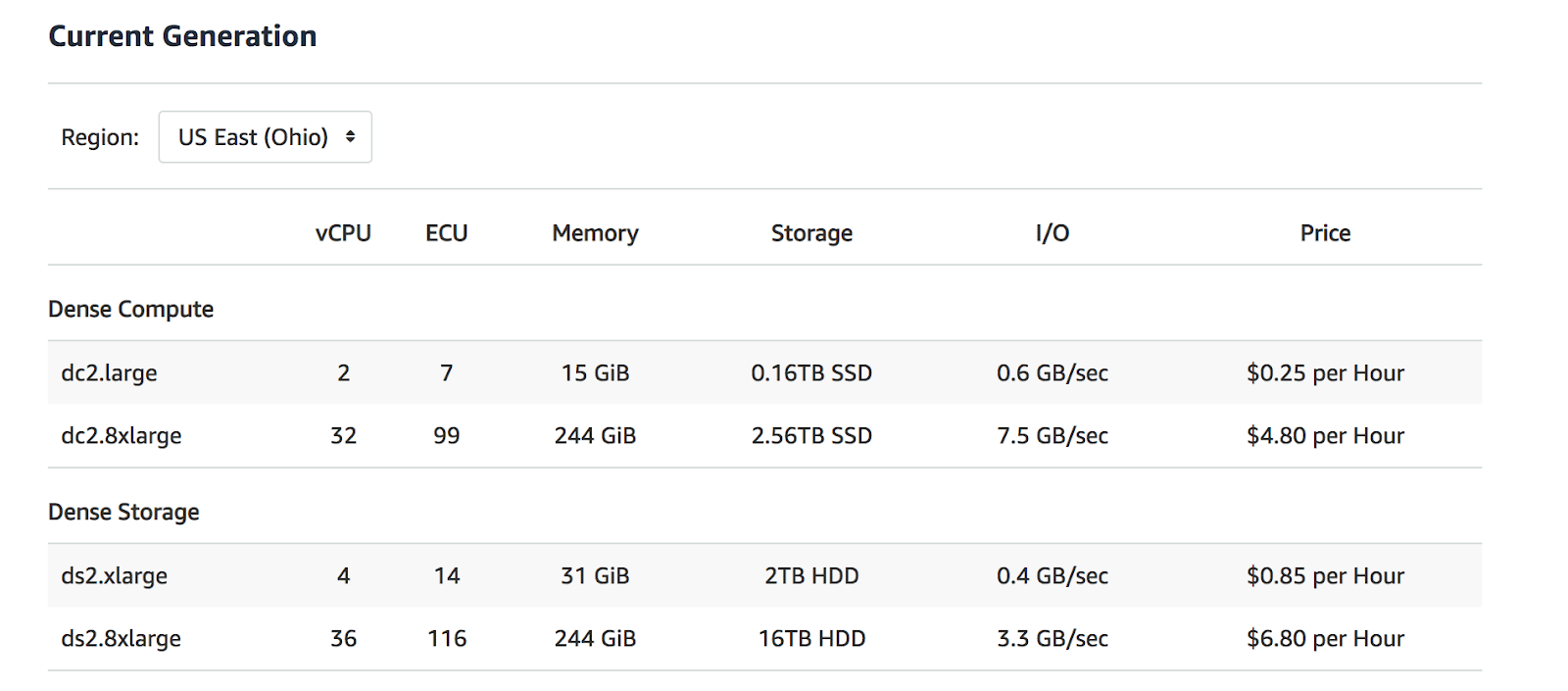
Amazon S3 is priced based on three different factors: the amount of storage, monthly outbound data transfers, and the monthly number of data requests. The cost of storage is based on the total size of the objects in gigabytes stored in the Amazon S3 buckets, generally priced at $0.03/GB.
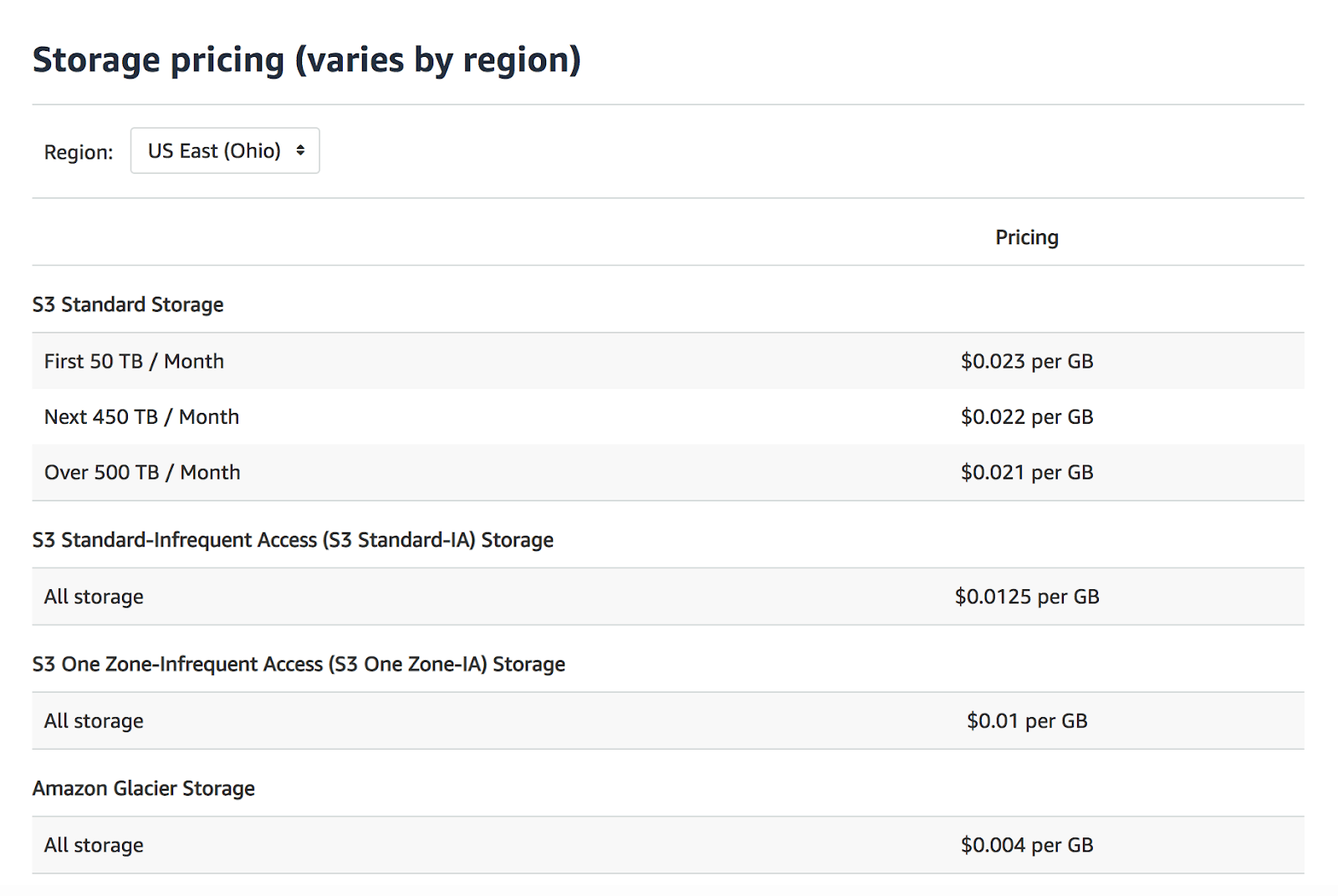
In short, data is more expensive to store in Redshift than in S3. Employing the pricing models above in a typical scenario, storing 2 TBs of data can cost $42 in S3 as opposed to $640 in Redshift.
AtScale solves for this pricing dichotomy by storing dimension tables in Amazon Redshift, while keeping raw data in Amazon S3.
Having dimensionality data on Amazon Redshift not only provides the benefits of a minimum footprint on AWS, but also avoids having to go back to Amazon Redshift to obtain results. AtScale makes use of the aggregates stored on Amazon S3 to produce results. Subsequent retrieval access is very fast and with the cost of a very small footprint. Once the aggregate table has been built, subsequent access to Amazon Redshift is avoided. This is an ideal model because it brings data movement to a minimum.
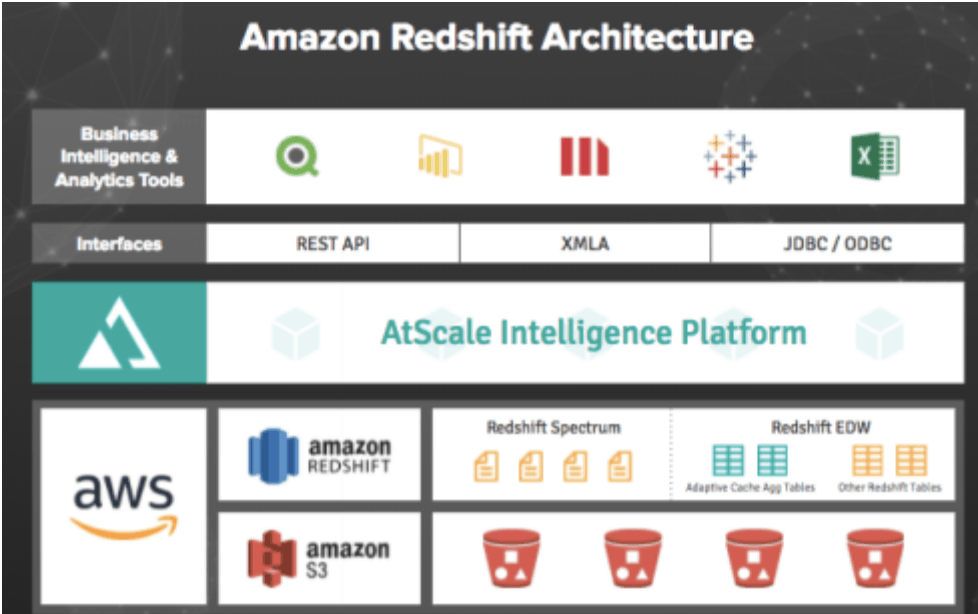
AtScale enables enterprises to realize these cost savings by utilizing machine learning to create, manage, and optimize aggregate tables. These tables contain measures from one or more fact tables and include aggregated values for these measures. The aggregation of the data is at the level of one or more dimensional attributes, or, if no dimensional attributes are included, the aggregated data is a total of the values for the included measures. AtScale aggregates reduce the number of rows that the query has to scan in order to obtain the results for the report or dashboard. By doing this, the length of time needed to produce the results will be dramatically reduced. This results in reduced latency and a significant reduction in cloud resource consumption, translating into increased savings.
“Read AtScale’s White Paper on Maximizing Business Value with Amazon Redshift”
SHARE
The Practical Guide to Using a Semantic Layer for Data & Analytics