
Introduction to Data Fabric
We have written about the concept of the “Data Fabric” in the past. While not new, it is an increasingly cited topic to help organize the many technologies and strategies employed by enterprise data teams to modernize their data and analytics capabilities. It was a popular topic at the recent Gartner Data & Analytics Summit. Gartner defines the data fabric as a, “design concept that serves as an integrated layer (fabric) of data and connecting processes.” In effect, it is a design pattern employed by enterprise data teams for allowing data producers and data consumers to interact with data. A highly capable data fabric has many benefits and enables a metadata-driven, semi-autonomous data discovery and processing pipeline.
Why should you care? According to a Gartner research note from December 2020 entitled “Emerging Technologies: data fabric Is the Future of Data Management,” “By 2024, more than 25% of data management vendors will provide a complete framework for data fabric support through a combination of their own products and partners, up from below 5% today.” In other words, this new design pattern is expected to have legs and technology providers are expected to add features to their products to support this framework.
There are numerous vendors in the data ecosystem today who are twisting the term data fabric within their marketing, causing a lot of confusion. In this post, I’ll explain the data fabric design pattern and propose some topics your organization should focus on now, and which to implement in the future. We’ll also dive more deeply into how a business-friendly data delivery capability and a metadata-driven, logical data model is an essential starting point for deploying a data fabric design.
What is Data Fabric?
Data fabric is a design concept for orchestrating a modern, self-service data infrastructure. Ultimately, the goal of a data fabric is to connect data producers and data consumers through a flexible, dynamic and metadata-driven architecture.
Data Fabric is a Design Pattern, and Not a Single Technology
First and foremost, data fabric is not a single piece of technology that fits nicely into a Gartner Magic Quadrant. While there may be vendors branding their solutions under the term “Data Fabric,” in reality, they are focused on one or two components of an enterprise data fabric. The key is to evaluate your data and analytics tooling vendors’ ability to work well within a data fabric architecture through interoperability.
Data Fabric is Comprised of Interoperable Components Connected by Metadata
The “thread” holding together data fabric is metadata. Metadata is created throughout the lifecycle of data – from capture, to preparation, modeling and serving. At each stage, metadata is both an input and an output of the tools interacting with the data pipeline. The ultimate goal of a mature data fabric is to create a fully autonomous data factory where each data “processor” can leverage metadata created from other components in the ecosystem. To achieve this vision, it’s essential to select technology solutions that can leverage metadata to drive their work, while sharing their metadata with other tools using open standards and APIs.
Components of a Data Fabric
A data fabric is “woven” together using a set of interoperable technology components. By leveraging open solutions, data teams can build data fabrics composed of best-of-breed technology components with the set of capabilities best suited for their use cases.
As defined by Gartner, there are five key technologies within a data fabric, woven together with data and metadata:
- Augmented Data Catalog
- Knowledge Graph
- Data Preparation & Delivery Layer
- Recommendation Engine
- Orchestration & DataOps
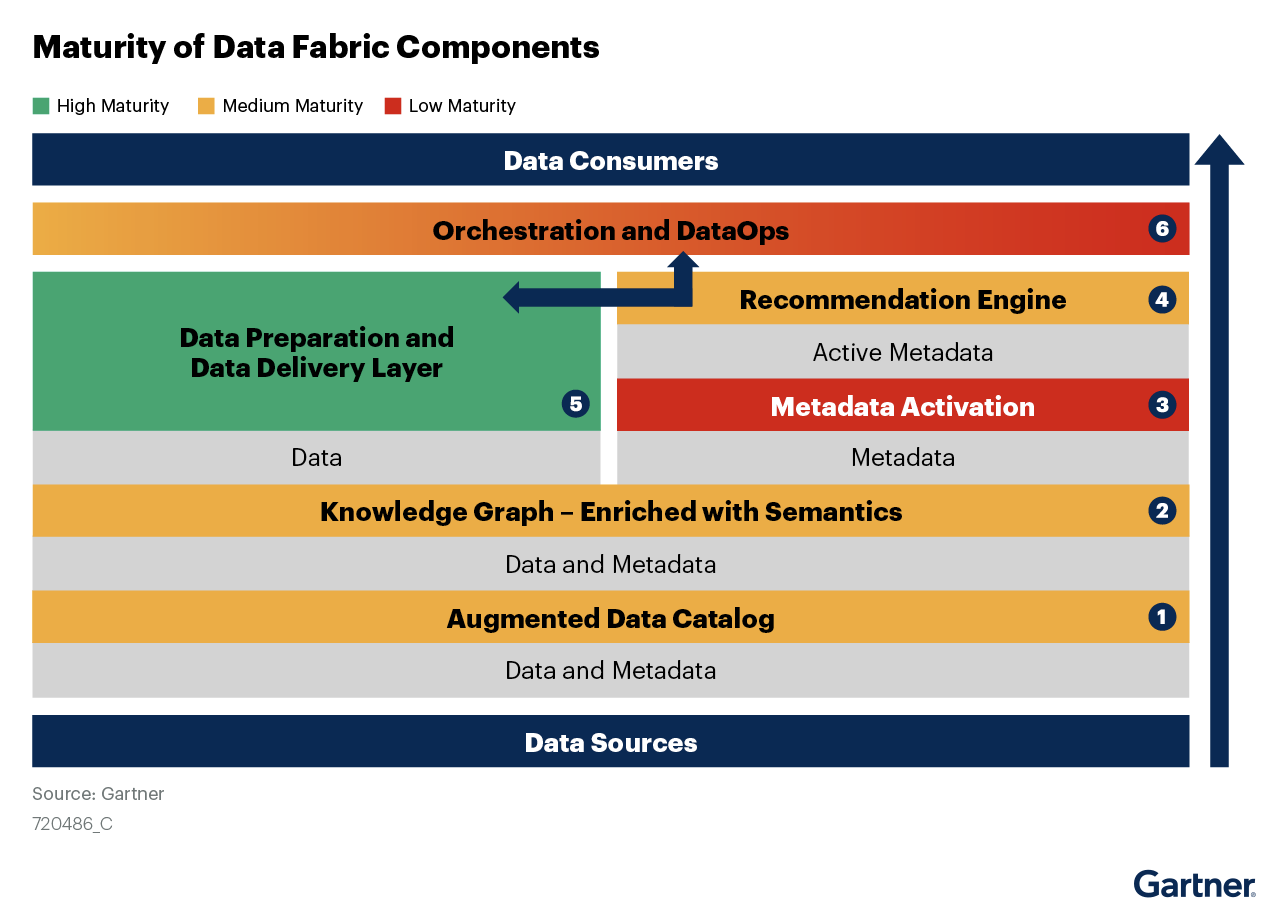
Image 1: Gartner’s Data Fabric Design
In the following sections, we will discuss each component and its role in creating an autonomous data and analytics pipeline. In addition, we will discuss the role of the semantic layer and how it compliments, contributes to and leverages the data fabric design.
Data and Metadata as “Threads” of the Data Fabric
Before we dive into the functional components, let’s first discuss the “threads” of data and metadata that serve as the connective tissue of an enterprise data fabric. It is useful to split both data and metadata into two types, related to how it is transformed or prepared for consumption.
| Data Category | Data Type | Description | Examples |
| Data | Raw | Data as it is captured from operational systems (Unaltered) | cookie_id, customer_first_name |
| Prepared | Data that has been transformed, cleansed or created from other data in preparation for a particular consumption use case (i.e. data science, business intelligence) | cleansed customer address, total_ | |
| Metadata | Operational | Data captured from tooling or systems used to process data | Table names, column names, table row count |
| Business | Business-friendly terms, data hierarchies for describing business processes | Enterprise KPIs (e.g., Gross Revenue, ARR), Conformed Dimensions (e.g. Sales Region |
Table 1: Data Type Definitions
Gartner also further breaks down metadata into two types, “active” and “passive”. Passive metadata refers to design-based metadata (i.e., data models, schemas, glossaries) and runtime metadata (logs, audit information). Active metadata is AI-driven and refers to the continuous analysis of data usage to determine whether the system requirements are being met. This type of metadata is called “active” because it should drive machine learning-based, autonomous adjustments to processes in order to match the data fabric’s design goals. In both cases, metadata is the glue and it’s fundamental to weaving together the components of a data fabric.
Augmented Data Catalog and the Data Fabric
The enterprise data catalog is the foundational component of the data fabric. If you Google the term “data catalog,” you’ll get the following definition from Oracle:
“Simply put, a data catalog is an organized inventory of data assets in the organization. It uses metadata to help organizations manage their data. It also helps data professionals collect, organize, access, and enrich metadata to support data discovery and governance.”
That’s a pretty good summary of what an enterprise data catalog is and does. More specifically, the data catalog is responsible for the following activities:
- It creates an inventory of data assets by crawling enterprise repositories for data sources
- It extracts operational metadata from data sources and stores them in a repository
- It automatically tags datasets with metadata using machine learning rules
- It provides an environment for users to document, rate and converse about datasets
- It provides a context-sensitive search index to allow users to find data
You can see that the enterprise data catalog is really the starting point for a data fabric design, because it creates an inventory of data assets and a repository for documenting and sharing information about those data assets. This is critical metadata that can drive the functionality for all of the other components in our data fabric design.
Knowledge Graph and the Data Fabric
Knowledge graphs seek to uncover entity connections and quantify their relative connection strengths in order to identify relationships in data.
In a data fabric design, knowledge graphs are ideal for identifying data relationships across multiple silos and can be used to enforce consistency and compliance. By creating contextual maps, knowledge graphs can be used to power machine learning and to automate the construction of data models.
Recommendation Engine in the Data Fabric
The recommendation engine in a data fabric design refers to any engine or process that can leverage “active” metadata to adjust and suggest changes in data integration processes. The recommendation engine can take the form of a vendor-based solution or be the results of machine learning models to identify improvements or surface anomalies (i.e., data quality failures) in the data preparation process.
Data Preparation & Data Delivery
The data preparation and data delivery components of a data fabric are actually a broad set of technologies used for executing data transformations and data integrations during the lifecycle of the data pipeline.
Data preparation begins with the loading of data into a data platform from raw files or a data lake. The loading of data may take the form of a batch load process or streaming input for real time or near real time data. Depending on the tooling or preference, data may be transformed using an Extraction/Transformation/Load (ETL) style, or the more modern ELT style. The diagram below illustrates the difference between the two methods, ETL vs. ELT.
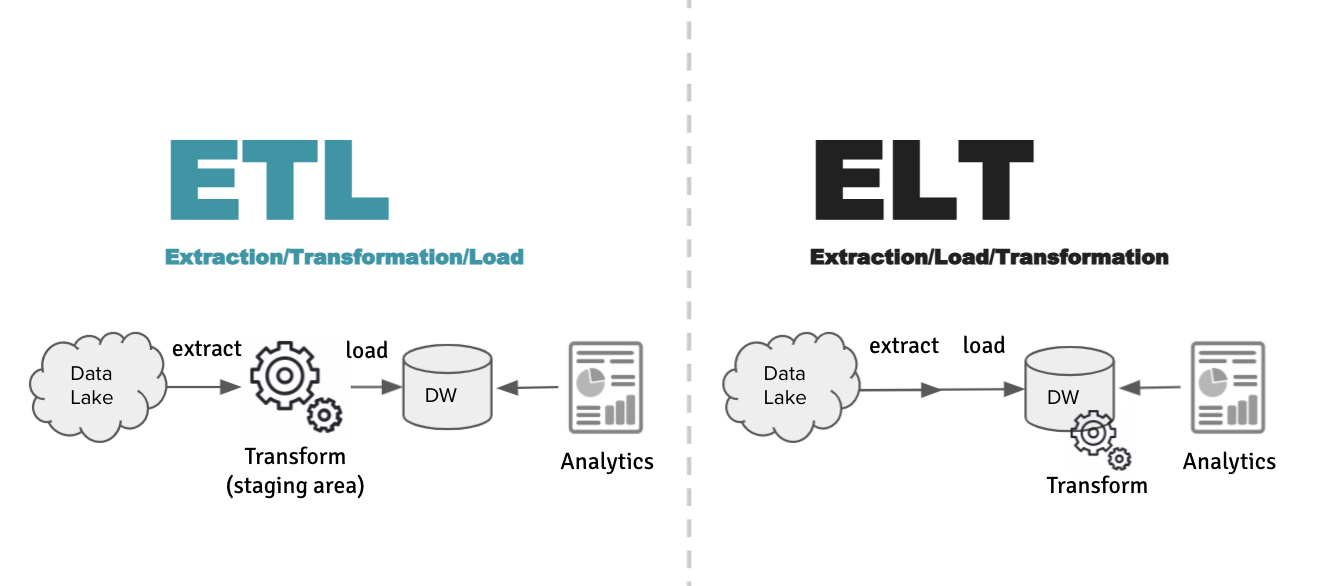
Image 2: Data Integration Styles
Essentially, in the ETL style, data transformations are processed outside of the data platform before loading data. In the ELT style, the raw data is loaded first into the data platform and transformations are performed inside the data platform using SQL. In either case, the result of the data transformations is what we called “prepared data” in our data fabric chart above.
Special Note: There is another data integration style called “data virtualization.” When data virtualization is used for data integration, transformations are performed virtually during query time. Data virtualization effectively collapses data preparation into the data delivery layer.
Data Orchestration & DataOps
Data orchestration refers to the systems and processes used to drive the data preparation workflow. Often, organizations use the orchestration functionality that’s built into their data prep tools. In other cases, organizations may deploy a separate open source job management framework like Apache Airflow, Jenkins or Apache Oozie to manage the data preparation lifecycle.
The term “DataOps” refers to the application of the DevOps-like principles of CI/CD (continuous integration, deployment) to data pipeline orchestration. By adopting DataOps, organizations apply product development practices to their data pipeline to deliver a more agile and rigorous data delivery practice.
Next Steps
As you can see, a data fabric design done properly, powered by metadata, can transform a legacy, manual data pipeline into a self-managing data service. The data fabric design is ambitious for sure and not something that you can implement overnight. However, charting a course using this design pattern should inform and drive your technology selections. By making sure each component in your data fabric can consume and share metadata, you can build the foundation for an agile and highly automated data service to support the full range of data and analytics use cases.
In my upcoming posts, I will be diving more deeply into the role of the semantic layer in a data fabric design and exploring practical strategies for building highly capable data infrastructures.

SHARE
Whitepaper | Enterprise Semantics for Power BI