
Trystan here, Software Engineer and doer of all things technical at AtScale. Which SQL-on-Hadoop engine performs best? We get this question all the time!
We looked around and found that no one had done a complete and impartial benchmark test of real-life workloads across multiple SQL-on-Hadoop engines (Impala, Spark, Hive…etc).
So, we decided to put our enterprise experience to work and deliver the world’s first BI-on-Hadoop performance benchmark.
What did we find out? Well, turns out that the right question to ask is: “Which engine performs best for Which query type?”. We looked across three of the most common types of BI queries and found that each engine had a particular niche. Bottom line: One Engine does NOT fit all.
Read on to find out the details of our environment and configuration, the types of queries we tested.
In this benchmark, we evaluated three SQL-on-Hadoop engines against a set of performance criteria that represent typical workloads and query patterns for Business Intelligence use cases.
A quick background on BI, BI-on-Hadoop and SQL-on-Hadoop
Business Intelligence is a concept that’s been established for decades. But just as business users started to get value out of business intelligence tools, Hadoop emerged and changed the game. With Hadoop adoption on the rise, enterprises now need to figure out how to bring their business intelligence capabilities to bear against massive data volumes, growing data diversity, and increasing information demands. In fact, a recent survey conducted by AtScale, Cloudera, Hortonworks and Tableau revealed that BI is the TOP use case for Hadoop. Existing BI tools have struggled to deliver against these demands for information – suffering from slow response times, lack of agility, and inability to support modern data types.
AtScale’s approach to BI-on-Hadoop extensively leverages the rapidly improving and developing set of SQL engines now available in the ecosystem. Often, our customers ask us for advice or recommendations on which SQL engine performs best – the simple answer is that there is no “one size fits all” solution. To help answer the types of questions we get, we’ve developed a first set of BI-on-Hadoop benchmarks for 3 SQL engines: Hive Tez, Impala, and Spark SQL.
A framework for evaluating SQL-on-Hadoop engines
Based upon our experience working with a large number of companies across financial services, healthcare, retail, and telco we have developed a framework for evaluating SQL-on-Hadoop engines.
There are other publicly available SQL-on-Hadoop benchmarks that look at other aspects of these tools, such as breadth of SQL syntax support and performance for Data Science queries to name a few. However, the methodology behind the AtScale Business Intelligence benchmark focuses on traditional OLAP-style (On-Line Analytical Processing) queries that make extensive use of aggregation functions, GROUP BYs and WHERE clauses.
When evaluating SQL-on-Hadoop engines and their fitness to satisfy Business Intelligence workloads we look at three key areas of performance:
- Performs on Big Data: the SQL-on-Hadoop engine must be able to consistently analyze billions or trillions of rows of data without generating errors and with response times on the order of 10s or 100s of seconds.
- Fast on Small Data: the engine needs to deliver interactive performance on known query patterns and as such it is important that the SQL-on-Hadoop engine return results in no greater than a few seconds on small data sets (on the order of thousands or millions of rows).
- Stable for Many Users: the engine must be able to support concurrent queries issued by multiple users (10s, 100s and even 1000s of users) and perform reliably under highly concurrent analysis workloads.
Cluster environment and configurations
In order to evaluate the base performance of the SQL-on-Hadoop engines we configured Cloudera Impala, Hive-on-Tez, and Spark SQL on identical 12-node Hadoop clusters. Cluster setup:For our test environment we used an isolated 12 node cluster 1 master node, 1 gateway node and 10 data nodes.
For details on the specific configuration, download the benchmark whitepaper.
TPCH + BI oriented data layout
*__This benchmark data set is based on the widely-used TPCH data set, but has been modified to more accurately represent a typical BI-oriented data layout. __ *
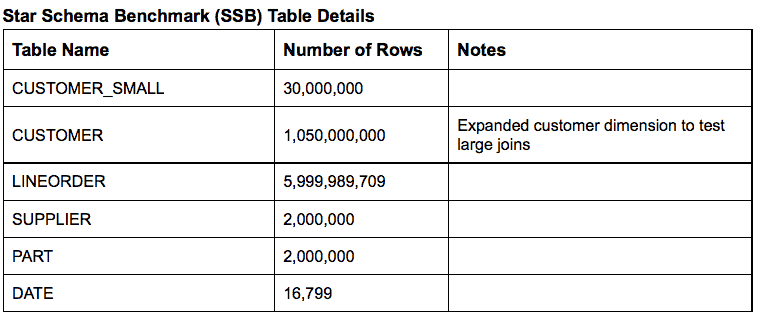
The testing team used the Star Schema Benchmark (SSB) data set, as described in greater detail here.
This data set allowed the team to test queries across large tables: the lineorder table contains close to 6 billion rows, the large customer table contains over a billion rows. The row counts for the tables used in the BI benchmarks are shown below.
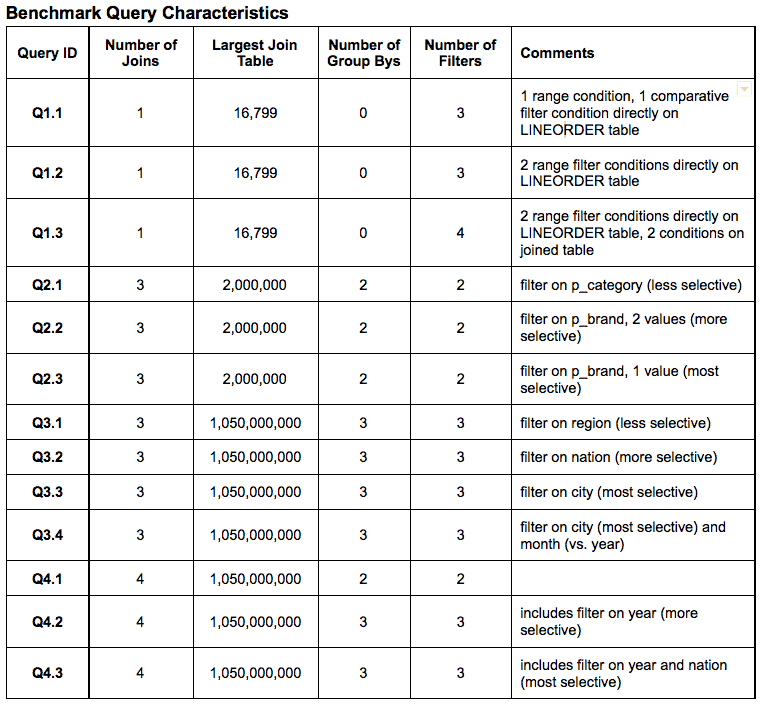
The testing team ran a set of 13 queries against each engine.
All queries were produced by the AtScale Engine based on Tableau Queries. The only differences between the queries between engines were semantic. The query characteristics are outlined below:
Benchmark Query Stats:
All 13 queries were executed twice:
- Once against the ‘large data set’
- Once against an ‘aggregated dataset’ (the tables comprising AtScale’s Adaptive Cache™ (created by the AtScale Engine based on the same set of 13 queries against the large dataset).
Each of the 13 individual queries was executed 10 times in succession; the numbers shown in the table below represent the average response time of the 10 queries.
Large Table Benchmark Observations:
The chart below shows the relative performance of Impala, Spark SQL, and Hive for our 13 benchmark queries against the 6 Billion row LINEORDERS table.
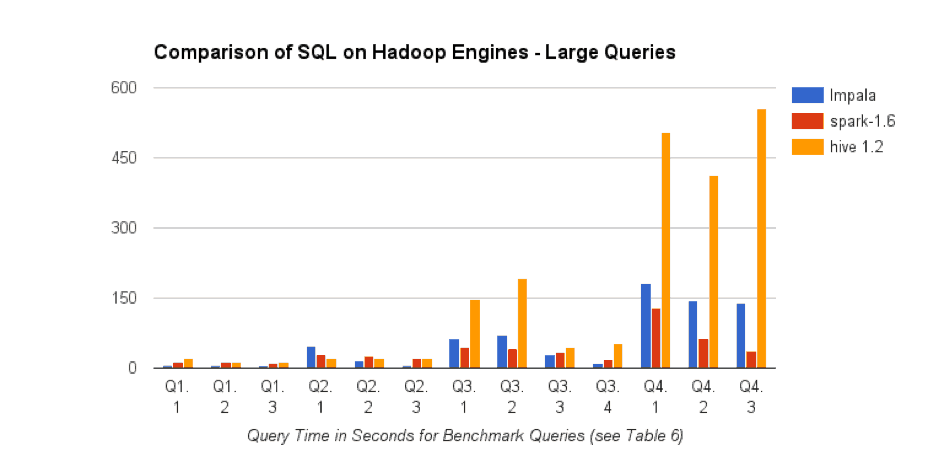
Based on the results of the Large Table Benchmarks, there are several key observations to note.
- No single SQL-on-Hadoop engine is best for ALL queries. Spark SQL and Impala tend to be faster than Hive, although for two queries (Q2.2, Q2.1) Hive is the fastest. For many queries, the performance difference between Impala and Spark SQL is relatively small.
- Increasing the number of joins generally increases query processing time. Going from “Quick Metric” to “Product Insight” queries (where the number of joins goes from 1 to 3) had the largest query time impact on Impala. However, as query selectivity increased, Impala performance increased significantly while Spark SQL and Hive performance remained relatively static.
- Increased query selectivity resulted in reduced query processing time (which may reduce the total amount of data that needs to be included in the query processing steps). Impala performance improved the most as query selectivity increased.
- As expected, including joins with very large tables resulted in increased query processing time for all engines. As expected, this was particularly true when involving the 1 Billion row CUSTOMERS table.
- As the number of joins increases, Spark SQL is more likely to be the best-performing engine, especially for less selective queries. We believe that recent improvements in Spark SQL 1.6 contribute to Spark SQL’s performance for multi-join queries.
Adaptive Cache™ Benchmark Observations:
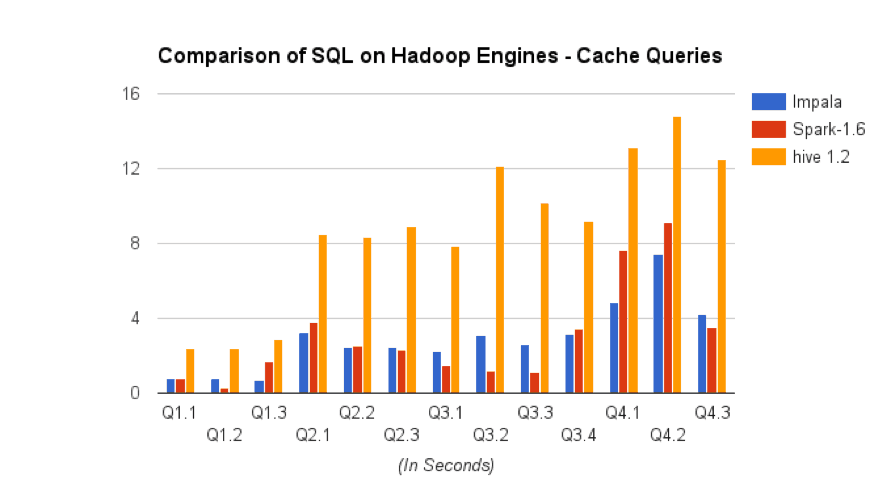
In order to evaluate each of the engines for the benchmarks the team re-executed the Large Table Queries after the tables comprising the AtScale Adaptive Cache were generated.
Our benchmark results indicate that both Impala and Spark SQL perform very well on the AtScale Adaptive Cache, effectively returning query results on our 6 Billion row data set with query response times ranging from from under 300 milliseconds to several seconds. As expected, Hive queries against the Adaptive Cache were slower, ranging from 3 to 15 seconds. Note that a future version of Hive will incorporate a project called LLAP (long-lived query execution) that is expected to significantly reduce Hive execution time on smaller data sets.
Our benchmark results also illustrate the significant performance gains that can be realized from AtScale’s Adaptive Cache technology times, with query performance for the same query improving by as much as 50X. In real-life deployments on larger data sets (on the order of 100s of Billions of rows) AtScale customers have seen performance gains over 100-200X as a result of this technology.
When it comes to testing systems like Hadoop for Business Intelligence scenarios, concurrency is a key factor to consider.
We executed three sets of concurrency tests with 5, 10 and 25 concurrent users, where each “user” would run through the set of 13 queries based on the aggregated dataset. As can be seen below, increasing the number of concurrent users increases the average response time for all query engines.
Average Query Response Time for All Queries vs. User Concurrency:
EngineQueryPerformance_ConcurrentUsers.png
While it is worth noting that ALL engines were able to scale to support up to 25+ concurrent users without a single query failure, we observed different behaviors from the various engines tested: Impala demonstrates a better concurrent user scaling approach than Spark SQL or Hive. These results are consistent with our existing real-world experience with Impala concurrency scaling.
In Summary:
At a high level, this Benchmark study revealed the following about the current state of SQL-on-Hadoop engine:
- Different engines perform well for different types of queries: For large data sets Hive, Impala, and Spark SQL were all able to effectively complete a range of queries on over 6 Billion rows of data. The “winning” engine for each of our benchmark queries was dependent on the query characteristics (join size, selectivity, group-bys).
- In general Spark SQL and Impala perform best on small data sets: For small data sets we found that Spark SQL and Impala could consistently deliver response times in only a few seconds (or even a few 100 milliseconds)
- Impala scales with concurrency better than Hive and Spark: production enterprise BI user-bases may be on the order of 100s or 1,000s of users. As such, support for concurrent query workloads is critical. Our benchmarks showed that Impala performed best – that is, showed the least query degradation – as concurrent query workload increased.
- There is rapid innovation in the open source space, as seen by Spark SQL improvements, even from 1.5 to 1.6: we were surprised to find significant performance improvements between Spark 1.5 and Spark 1.6 – we believe that the active open source ecosystem has contributed to the rapid innovation in this space. As such we applaud Cloudera’s recent decision to donate Impala to the Apache Foundation – our experience is that the open source community contributes greatly to the improvements of the SQL-on-Hadoop engines at a velocity that exceeds what any single vendor can deliver.
- All engines are stable enough to support BI on Hadoop workloads: Although there are differences across the 3 engines tested, we found that Hive, Impala, and Spark SQL are all potential solutions to support BI on Hadoop workloads. However…
- A successful BI on Hadoop architecture will likely require more than one SQL on Hadoop engine: We did see various strong points for each of the engines, whether Impalas concurrency scaling support, Spark SQLs handling of large joins, or Hive’s consistency across multiple query types. Our belief is that a preferred approach to BI on Hadoop may be to leverage different engines for different query patterns, while providing an abstract query layer for business users that shields end-users from needing to be aware of this fact.
So, that’s what we found. Hope you find this as interesting and useful as we did. Let us know what you think, or ping us if you have questions.
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics