April 6, 2026
Best Data Governance Tools for Enterprises: 2026 GuideA Data Fabric is a framework and network–based architecture (vs point-to-point connections) for delivering large, consistent, integrated data from a centralized technology infrastructure using a hybrid cloud. A data fabric is an architecture and set of data services that provide consistent capabilities across a choice of endpoints spanning hybrid multi-cloud environments. This enables an integrated data layer (fabric) to be provided from multiple data sources to support analytics, insight generation, orchestration, and applications. The Data Fabric can be viewed as the centralized technology that enables a Data Mesh.
Purpose
The purpose of the Data Fabric is to deliver large, consistent, integrated data from a centralized technology infrastructure, particularly from a cloud / multi-cloud hybrid environment. Data Fabrics are designed to deliver availability, accuracy, efficiency, and consistency with cost effectiveness, and are particularly beneficial for delivering large, integrated data and tools for business intelligence and analytics, where data size, reporting, and analysis needs commonality, and data accuracy, availability, and consistency are most important.
Key Capabilities to Consider when Implementing a Data Fabric
- An enterprise data fabric focuses on providing large, enterprise-wide integrated data sets, focusing on availability, accuracy, and consistency from a single, integrated, automated set of data management technologies.
- A data fabric core technology infrastructure is centralized to ensure that data and applications are governed and synchronized.
- Data Fabrics are designed to work in the cloud, particularly public and hybrid clouds.
- A data fabric can be a data delivery technology architecture to support a data mesh.
- A data fabric utilizes continuous analytics over existing, discoverable metadata assets to support the design, deployment, and utilization of integrated and reusable data across all environments, including hybrid and multi-cloud platforms.
- A data fabric leverages both human and machine capabilities to access data in place or support its consolidation where appropriate.
- A data fabric continuously identifies and connects data from disparate applications to discover unique, business-relevant relationships between the available data points.
- The architecture supports faster decision-making, providing more value through rapid access and comprehension than traditional data management practices.
According to Gartner, the key pillars of a data fabric are as follows:
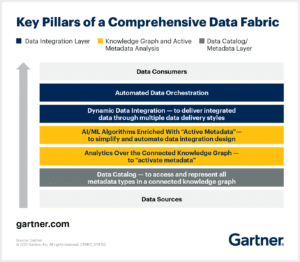
Primary Uses of a Data Fabric
A data fabric is used to increase scale, consistency, and cost effectiveness of delivering large, integrated datasets from a common set of data management capabilities from a multi-cloud environment. he enterprise. The data mesh framework and architecture are most appropriate when the business domains have diverse needs in terms of the data, insights, and analytics that they use, such that centralized data, reporting, and analysis are not required or beneficial. The data mesh requires the following capabilities
- Singular set of common data management capabilities designed to deliver ready-to-analyze datasets from a hybrid-cloud environment
- Centralized data governance, including centralized data catalogs and a semantic layer
- Centralized IT team focused on providing and supporting conformed data availability (e.g., from data lake / data warehouse)
- Centralized IT utilizing a common set of data / data product capabilities
- Processes are consistent and automated to improve the speed of data delivery
A data fabric can be the technology to provide data to enable Data Products creation. Data Products are a self-contained dataset that includes all elements of the process required to transform the data into a published set of insights. For a Business Intelligence use case, the elements are data set creation, data model / semantic model, and published results, including reports and analyses that may be delivered via spreadsheets or a BI application. Examples of data products are shown below.

Key Business Benefits of a Data Fabric
The main benefits of a data fabric are increased speed, scale, availability, accuracy, and consistency to deliver / make available ready-to-analyze integrated data to users.
Common Roles and Responsibilities Associated with a Data Fabric
Roles important to a data fabric are as follows:
- Insights Creators – Insights creators (e.g., data analysts) are responsible for creating insights from data and delivering them to insights consumers. Insights creators typically design the reports and analyses, and often develop them, including reviewing and validating the data. Insights creators are supported by insights enablers.
- Insights Enablers – Insights enablers (e.g., data engineers, data architects, BI engineers) are responsible for making data available to insights creators, including helping to develop the reports and dashboards used by insights consumers.
- Insights Consumers – Insights consumers (e.g., business leaders and analysts) are responsible for using insights and analyses created by insights creators to improve business performance, including through improved awareness, plans, decisions, and actions.
- BI Engineer – The BI engineer is responsible for delivering business insights using OLAP methods and tools. The BI engineer works with the business and technical teams to ensure that the data is available and modeled appropriately for OLAP queries, and then builds those queries, including designing the outputs (reports, visuals, dashboards) typically using BI tools. In some cases, the BI engineer also models the data.
- Business Owner – There needs to be a business owner who understands the business needs for data and subsequent reporting and analysis. This is to ensure accountability, actionability, as well as ownership for data quality and data utility based on the data model. The business owner and project sponsor are responsible for reviewing and approving the data model as well as the reports and analyses that OLAP will generate. For larger, enterprise-wide insights creation and performance measurement, a governance structure should be considered to ensure cross-functional engagement and ownership for all aspects of data acquisition, modeling, and usage: reporting, analysis.
- Data Analyst / Business Analyst – Often a business analyst or more recently, data analyst are responsible for defining the uses and use cases of the data, as well as providing design input to data structure, particularly metrics, business questions / queries and outputs (reports and analyses) intended to be performed and improved. Responsibilities also include owning the roadmap for how data is going to be enhanced to address additional business questions and existing insights gaps.
Strategic Business Applications of a Data Fabric
A data fabric architecture empowers organizations to overcome data fragmentation and harness insights from distributed sources. By virtualizing access to siloed data, businesses address critical challenges across industries through these key applications:
- Unified Customer Insights – Retailers and financial institutions merge CRM data, transaction histories, and social media interactions into a single virtual layer. This 360-degree view enables personalized marketing and churn prediction without physical data movement.
- Real-Time Supply Chain Optimization – Manufacturers integrate IoT sensor data, inventory systems, and supplier APIs via a data fabric. Teams monitor production lines and logistics in real time, adjusting workflows to prevent delays.
- AI/ML Readiness at Scale – Healthcare providers unify EHRs, lab results, and genomic datasets through a data fabric. Structured, governed feeds accelerate the training of diagnostic AI models while maintaining HIPAA compliance.
- Predictive Maintenance – Energy companies analyze equipment sensor data alongside maintenance logs. Machine learning models forecast failures days in advance, which significantly reduces unplanned downtime. Manufacturers apply similar frameworks to preemptively replace worn components and extend the life span of costly assets.
- Fraud Detection Acceleration – Banks process transaction streams, user behavior analytics, and external threat feeds through a data fabric. Anomaly detection algorithms flag suspicious activity in milliseconds, slashing fraud losses. Credit card companies use this to block risky transactions without disrupting legitimate purchases.
- Agile Regulatory Reporting – Global enterprises auto-generate compliance reports by virtualizing financial data across regions. A data fabric ensures adherence to GDPR and SOX while eliminating manual aggregation. Healthcare networks automate audit trails for patient data access and cut compliance prep time.
- Scalable Hybrid Cloud Operations – Organizations using hybrid cloud models leverage data fabrics to unify edge, on-premises, and cloud data. Logistics firms process IoT shipment data at the edge while synchronizing with central cloud analytics, balancing real-time responsiveness with cost efficiency.
AtScale enhances data fabric implementations through its semantic layer, which adds a metrics governance framework to virtualized data. According to Dave Mariani, AtScale’s Co-Founder and CTO, “While there may be vendors branding their solutions under the term ‘Data Fabric,’ in reality, they are focused on one or two components of an enterprise data fabric. The key is to evaluate your data and analytics tooling vendors’ ability to work well within a data fabric architecture through interoperability.”
Common Technologies associated with a Data Fabric
Technologies involved with a Data Fabric are as follows:
- Data Products – Data Products are a self-contained dataset that includes all elements of the process required to transform the data into a published set of insights. For a Business Intelligence use case, the elements are data set creation, data model / semantic model, and published results, including report analyses that may be delivered via spreadsheets or a BI application.
- Data Preparation – Data preparation involves enhancing it and aggregating it to make it ready for analysis, including addressing a specific set of business questions.
- Data Modeling – Data modeling involves creating structure and consistency as well as standardization of the data via adding dimensionality, attributes, metrics, and aggregation. Data models are both logical (reference) and physical. Data models ensure that data is structured in such a way that it can be stored and queried with transparency and effectiveness.
- Database – Databases store data for easy access, profiling, structuring, and querying. Databases come in many forms to store many types of data.
- Data Querying – Technologies called Online Analytical Processing (OLAP) are used to automate data querying, which involves making requests for slices of data from a database. Queries can also be made using standardized languages or protocols such as SQL. Queries take data as an input and deliver a smaller subset of the data in a summarized form for reporting and analysis, including interpretation and presentation by analysts for decision-makers and action-takers.
- Data Warehouse – Data warehouses store data that are used frequently and extensively by the business for reporting and analysis. Data warehouses are constructed to store the data in a way that is integrated, secure, and easily accessible for standard and ad-hoc queries for many users.
- Data Lake – Data lakes are centralized data storage facilities that automate and standardize the process of acquiring, storing, and making data available for profiling, preparation, data modeling, analysis, and reporting / publishing. Data lakes are often created using cloud technology, which makes data storage very inexpensive, flexible, and elastic.
- Data Catalog – These applications make it easier to record and manage access to data, including at the source and dataset (e.g., data product) level.
- Semantic Layer – Semantic layer applications enable the development of a logical and physical data model for use by OLAP-based business intelligence and analytics applications. The Semantic Layer supports data governance by enabling management of all data used to create reports and analyses, as well as all data generated for those reports and analyses, thus enabling governance of the output / usage aspects of input data.
- Data Governance Tools – These tools automate the management of access to and usage of data. They can also be used to manage compliance by searching across data to determine if the format and structure of the data being stored complies with policies..
- Business Intelligence (BI) Tools – These tools automate the OLAP queries, making it easier for data analysts and business-oriented users to create reports and analyses without having to involve IT / technical resources.
- Visualization tools – Visualizations are typically available within the BI tools and are also available as standalone applications and as libraries, including open source.
- Automation – Strong emphasis is placed on automating all aspects of the process for developing and delivering integrated data sets from hybrid-cloud environments.
Future Trends in Data Fabric Architecture
Data fabric architectures are evolving rapidly to address growing data complexity and the demand for real-time insights. These trends will define their development through 2025 and beyond:
- AI and Machine Learning Integration – AI will automate metadata management and pipeline optimization, enabling data fabrics to predict trends and self-adjust workflows. Machine learning models will process unified datasets to deliver prescriptive insights, transforming raw data into decision-ready recommendations.
- Augmented Analytics – Natural language interfaces will allow users to query data through conversational prompts, while AI-generated insights highlight anomalies and opportunities directly within dashboards. These tools bridge the gap between technical and non-technical teams, which will accelerate time-to-insight.
- Data Democratization – Self-service portals will empower business teams to explore governed datasets without coding expertise, supported by unified metric definitions that ensure consistency across tools. Democratization fosters agility while maintaining centralized control over data quality.
- Data Governance and Compliance – Automated classification and lineage tracking will simplify adherence to regulations like GDPR and HIPAA. Data fabrics will embed privacy controls during ingestion, redacting sensitive details, and generating audit trails without manual oversight.
- Edge Analytics Integration – Real-time processing at the edge will enable instant actions, such as equipment shutdowns or fraud alerts, while federated learning syncs localized insights to central systems. This balances responsiveness with resource efficiency in distributed environments.
- Growth of Data Lakes and Hybrid Cloud Solutions – Data fabrics will unify structured and unstructured data across lakes, warehouses, and edge systems. Hybrid architectures optimize costs by dynamically routing workloads between cloud and on-premises resources.
- Data Fabric as the Primary Architecture – Enterprises will increasingly adopt data fabric architecture as core infrastructure, replacing siloed pipelines with interconnected, intelligent workflows. Its ability to virtualize access while enforcing governance positions it as the foundation for scalable AI and analytics.
AtScale and Data Fabrics
The AtScale semantic layer platform improves data fabric implementation by enabling faster insights creation via rapid data modeling for AI and BI, including performance via automated query optimization. The semantic layer enables the development of a unified business-driven data model that defines what data can be used, including supporting specific queries that generate data for visualization. This enables ease of tracking and auditing, and ensures that all aspects of how data are defined, queried, and rendered across multiple dimensions, entities, attributes, and metrics— including the source data and queries made to develop output for reporting, analysis, and analytics — are known and tracked. Watch AtScale in action or reach out for more information.
SHARE
Guide: How to Choose a Semantic Layer