
In our first post of this series, we explored the notion of a Data Fabric as a design pattern for assembling technologies and processes to support modern data and analytics infrastructure.
Now that we better understand what data fabric is all about, it’s time to dive into how data fabric plugs into data consumption. After all, the data fabric design pattern primarily focuses on data preparation and data pipelines, not data consumption: in contrast, a semantic layer enhances and feeds off of a data fabric design to complete the data and analytics journey.
Not only does the semantic layer play a critical role in data consumption, it also interacts through data and metadata with the data fabric in the following steps.
- First, the semantic layer consumes data fabric metadata to autonomously inform and create the logical data model.
- Second, the semantic layer feeds metadata back to the data fabric by delivering query and data usage statistics.
- Third, the semantic layer contributes data back to the data fabric by orchestrating the creation and ongoing maintenance of aggregates for performance acceleration.
- Finally, the semantic layer shares its metadata with the data catalog and knowledge graph components to enhance their respective knowledge about data relationships and data usage.
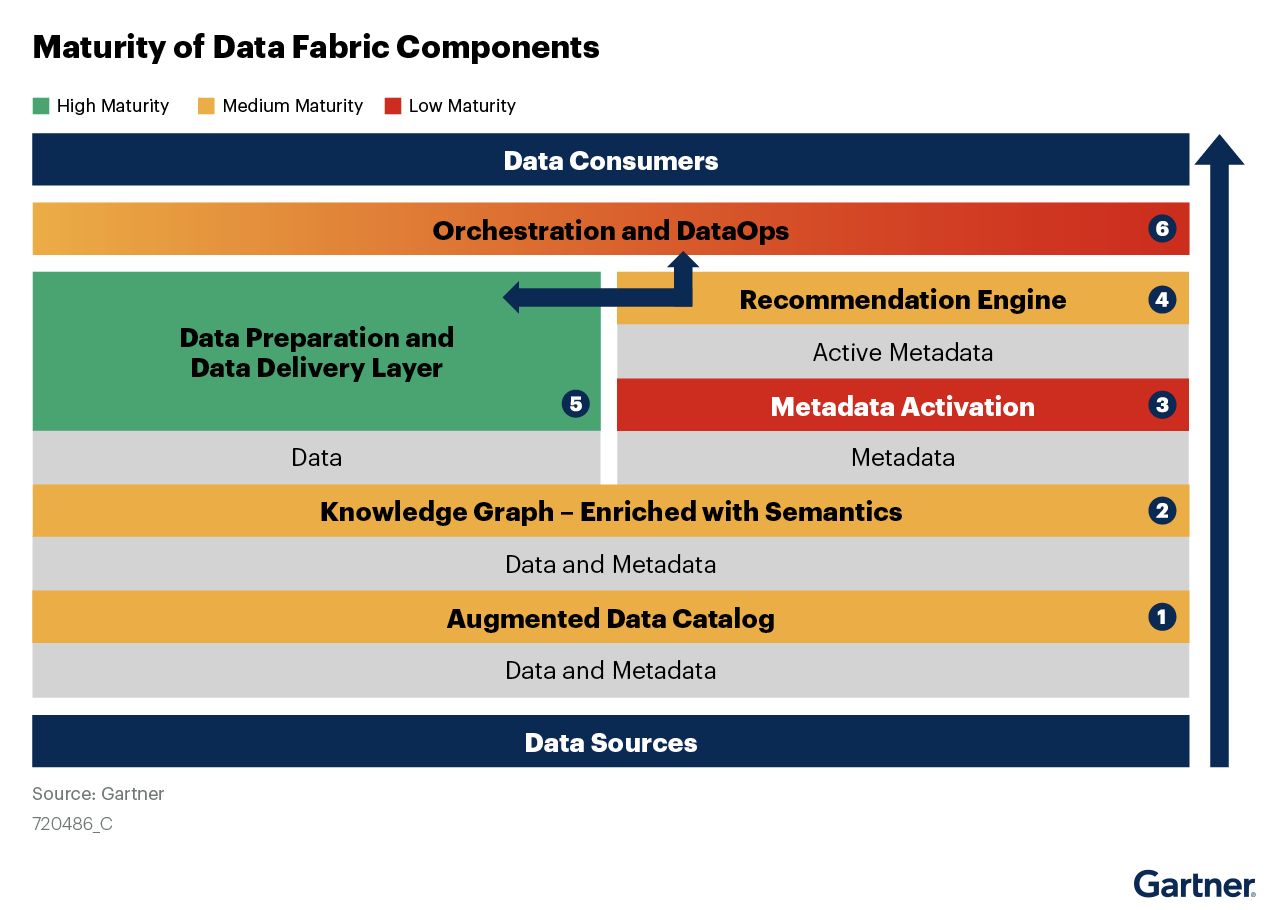
Image 1: How the Semantic Layer Interacts with Data Fabric
In addition to interchanging data and metadata with the data fabric, the semantic layer also plays two important roles in connecting users to data. First, the logical data model adds a business-friendly interface to raw data, making the data consumable by a wider range of approved users. Second, the data consumption layer serves as the “last mile” connecting users and their tools to the physical data––ensuring these users can not only understand but apply their data in key business contexts.
In the next two sections, we’ll delve deeper into these critical components.
Logical Data Model
Data models have been around forever. The purpose of a data model is to define relationships between entities so that data can be combined in a variety of ways. If you Google “data models,” you’ll get this pretty good definition from C3 AI:
“A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities.”
There are different types of data models, including conceptual data models and physical data models. In a data fabric design, the logical data model embodies both types of data models, bringing the two together to give you a more holistic insight or recommendation.
To get the most from your data, a logical data model first serves as a conceptual data model because it describes a business process like a “sales pipeline” and makes it “queryable,” or digital. Next, a logical data model will leverage a physical data model (i.e. tables, columns, key constraints) from the underlying data platform to construct a business data model to make data more friendly for consumers.
In short, the logical data model serves as the “digital twin” for the business, transforming abstract bits and bytes into actionable data that business users and data scientists can understand.
So where do data models live? You’ll find data models living in many places including within your database modeling tools, business intelligence tools, data preparation tools, AI/ML platforms––in other words, just about anywhere that data is accessed.
All these different, diverse data models can work in their own ways and their own systems. Therein lies both the problem and the opportunity.
In most enterprises, data models live in the consumption layer. But for a workable data fabric design, the data model needs to exist as its own component, in one place, separate from data consumption.
By pulling the data model out of the data consumption layer, a data fabric design can use the logical data model to deliver one map of your enterprise’s business processes and data. The result is a logical data model that delivers a consistent view of data for data consumers, all while automating data discovery and modeling for data producers.
Data Consumption Layer
You can think of the data consumption layer as the last mile for connecting consumers to the data. The data consumption layer is responsible for connecting the business-friendly logical data model we discussed above to the people and applications that need to query the data.
Of course, consumers using query tools or using raw queries can bypass the data consumption layer altogether and access the data in the data platforms directly. In fact, this is a very common practice for many organizations today. However, bypassing the data delivery component also means consumers are bypassing the logical data model–– rendering the semantic layer useless.
In this situation, consumers are left to their own devices to model data and define their own business terms and calculations – a recipe for chaos. Instead of clean, consistent and governed data, you’ll be relying on disparate data.
As you can see, the data consumption layer is essential to the data fabric design since it connects consumers to the logical data model.
In addition to delivering a consistent digital view of the business via the logical data model, data delivery is also responsible for query performance optimization and cost management. By rewriting incoming queries automatically to access optimized data structures (i.e. aggregates, materialized views, memory caches), the data consumption layer delivers faster query performance and reduces I/O on the underlying data platforms.
In other words, the data consumption layer serves as the analytics front end to the data fabric, providing a central point of control for applying optimizations and managing resource utilization.
Putting it All Together: A Real World Use Case
The most mature implementation of a data fabric design will include tools that can share their metadata with each other while applying that metadata to autonomously drive their workloads.
To describe how this could work, let’s take a real world example. Let’s assume that we have a new customer call center application that generates customer interaction data (raw data) in a cloud data warehouse and the data contains customer personally identifiable information (PII.)
With metadata-powered data fabric, the following diagram depicts how a data fabric design with compatible tooling can support this use case without manual human intervention:
| 1 | The enterprise data catalog will automatically surface the new customer interaction tables through its data warehouse crawler and automatically identify PII fields using a matching rule (operational metadata) and classify them with a “PII” tag (business metadata) |
| 2 | This “PII” metadata tag can then be shared with the data preparation tool to automatically mask (or obfuscate) the customer PII using a transformation rule (operational metadata) when creating derived tables (prepared data). |
| 3 | The logical data model platform can then link the new customer support interaction data with existing customer sales data to create a customer churn score (business metadata) and create new business friendly metrics (business metadata) using definitions stored in the data catalog. |
| 4 | Finally, the data delivery component can surface a new customer churn score for business users AND provide data scientists with access to raw customer support tables by masking PII (operational metadata) as defined by the enterprise data catalog (business metadata) |
As the example shows, a data fabric design with compatible tooling can upend the traditional manual data engineering processes we employ today. Instead of waiting for IT to process the data, the data fabric can consistently “do the right thing” every time autonomously, all without manual intervention.
Next Steps
When properly applied, a data fabric design augmented with a semantic layer can transform a legacy, manual data pipeline into a self-managing data service that makes data consumable by everyone, not just analytics experts. By coupling a data fabric design for managing your data factory with a semantic layer, you can build the foundation for an agile and highly automated data service to support the full range of data and analytics use cases.
In my next post, we can dive more deeply into how a semantic layer enhances a data fabric design and the five specific benefits it can produce for your business.

SHARE
Whitepaper | Enterprise Semantics for Power BI