
In the first post of this series on Data Fabrics, we defined the enterprise data fabric design pattern and how it can transform your data and analytics operations into a self managing, data factory. And, in our second piece, we explored where a semantic layer fits within (or alongside) the data fabric.
In this third post, we’ll dive more deeply into how a semantic layer enhances a data fabric design. We’ll learn why a business friendly, metadata-driven, semantic layer is an essential ingredient when deploying a data fabric design.
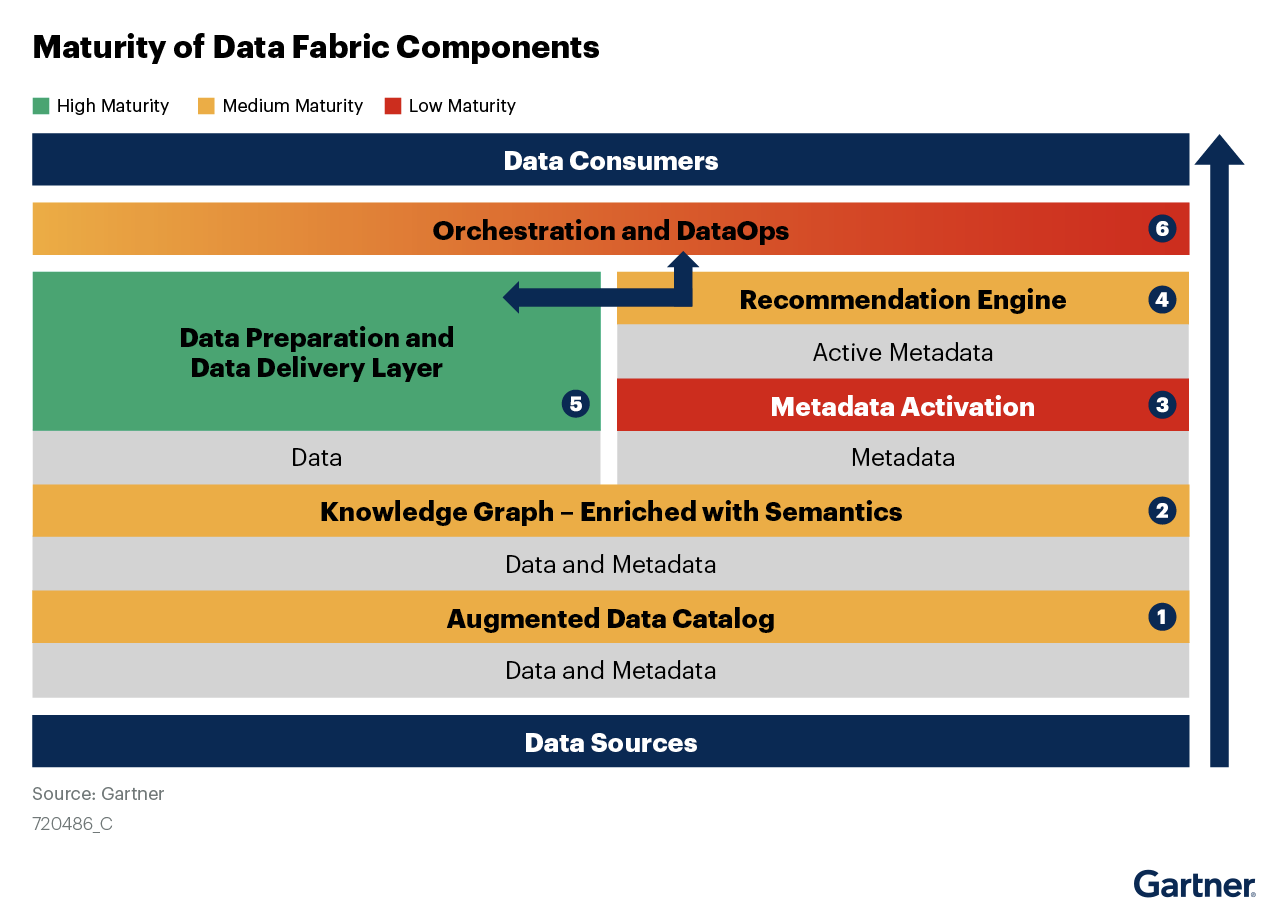
Image 1: The Semantic Layer & Data Fabric
The Semantic Layer
To summarize our second post, the semantic layer serves as the “digital twin” for your business. It transforms raw data, prepared data and metadata into a business friendly view to allow anyone in your organization to ask questions about the business.
Visibility and transparency are vital benefits for any company, and the following key points represent the five of the most significant benefits of a semantic layer.
1. It Is the Business View Of Your Data
The majority of information workers have little experience in data engineering and databases, which is understandable. After all, we shouldn’t require business users to become technical experts to get their questions answered. But data without metadata is data that is not fulfilling its potential, and too many businesses are leaving those opportunities behind due to the difficulty and complexity of parsing their information.
This is where the semantic layer comes in.
By creating a business-friendly data model that abstracts away the physical properties of data and the complexity of SQL, we can free the analytics consumer to focus on optimizing the business rather than optimizing queries. The logical layer dramatically simplifies business queries because it exposes a logical view of data using business- friendly terms.
For example, using this use case from Neil Barnett’s SQL primer, how would we write a SQL query to answer the question “How many employees started in the same month in the order they started that month?” to produce the output below:
| NumThisMonth | TheMonth | Firstname | Lastname |
| 1 | January 2019 | John | Smith |
| 1 | February 2019 | Sally | Jones |
| 2 | February 2019 | Sam | Gordon |
Without a semantic layer, we would expect an ordinary end user to write this SQL query:
SELECT COUNT(*) OVER (PARTITION BY MONTH(date_started), YEAR(date_started)
ORDER BY date_started) As NumThisMonth,
DATENAME(month,date_started)+’ ‘+DATENAME(year,date_started) As TheMonth,
firstname, lastname, date_started
FROM Employee
ORDER BY date_started;
Intuitive? Not exactly. SQL windowing functions like these, which are required for most time series analysis, are not for the faint of heart.
Instead, with a logical model, we could answer the same question with this query:
SELECT SUM(`Number of Employees`), `Month and Year`, `First Name`, `Last Name`
FROM `Employee`
GROUP BY `Month and Year`, `First Name`, `Last Name`;
The second query is much easier to read and understand because the transformations and windowing functions are defined in the model and the ordering is implicit since the model understands that the `Month and Year` column is a date hierarchy and thereby understands how to order the results accordingly (hence no ORDER BY clause is required.)
Just imagine if we had to join multiple tables for this query: the chaos of the previous example would spill over, slowing down your company and providing more opportunities for mistakes to be made. You can see how things can get quickly out of hand for even the most simple business queries.
Instead, a business-friendly model can hide all this complexity from users and ensure that everyone will get the same answers to the same questions.
2. It Is the Guard Rails for Analytics Self Service
Visualization vendors like Tableau pioneered the concept of “self service” by making their tools so easy to use. Instead of relying on IT for data, the business users themselves could explore their data as long as they had a connection to the company’s raw data. Unfettered access to raw data for producing analytics by ordinary users has its pros and cons.
The two main benefits of analytics self service are:
- Business users and data scientists are not held hostage to IT for their data needs
- IT is freed from creating dashboards and reports for a business process they often don’t understand
This adds up to an increase in agility to incorporate new data sources and make data-based decisions. However, there are unintended consequences for data self service as well.
The cons of analytics self service are:
- Lack of consistency since the data consumer can model data and create calculations differently for each report or analysis, leading to a lack of trust in analytics output
- Wasted productivity given the difficulty of reusing or leveraging the work of others when modeling data and creating calculations
- Hard to secure and govern data access since raw data is often stored in disparate data silos all with their own competing and overlapping data access rules
- Different tools and user personas (i.e. BI users, data scientists) are likely to generate different insights leading to bad business decisions
As a result, self service can often produce a chaotic, “anything goes” analytics environment which can lead to poor decisions and unacceptable risk for an organization.
So, how can you keep all the benefits of self-service without taking on the associated risks and challenges?
Fortunately, a semantic layer can deliver the benefits of self service while mitigating the drawbacks. A semantic layer embodies an organization’s business processes in a centrally managed, model-based repository, ensuring everyone is speaking the same language regardless of how they ask the question.
3. It Unifies Disparate Data Silos
As mentioned above, it is rare that data lives in one place. Even with the current wave of cloud data warehouse consolidation, data will always live in multiple platforms. Even the most centralized businesses likely have data tucked away in private clouds (think Salesforce) which are often only accessible via proprietary APIs.
In order to correctly answer a business question, a company nearly always requires a degree of data integration across multiple data silos.
A semantic layer coupled with data virtualization can solve this integration problem without ETL or costly, manual data engineering. With data virtualization, you can avoid the “early binding” problem that limits flexibility and creates complexity. And, instead of aggregating data early for a specific use case, a semantic layer defines graph-based data relationships to build aggregations only when, and if, they are needed.
This “late binding” approach means that data is accessible to your business users and data scientists at whatever granularity they need. Even better, your data consumers never need to know where the data is or how to query it using its particular data platform dialect.
This physical data abstraction future-proofs your investments in data platforms and simplifies data access for your data consumers. By providing a consistent dialect for asking questions, you can ensure you’re getting clear, correct and coherent answers.
4. It Reduces Manual Data Engineering Tasks
In today’s cloud data warehouse world, a database table is no longer just made up of simple rows and columns. Modern data warehouses now have advanced support for non-scalar data types like JSON and XML. Google BigQuery goes even further by allowing for nested and repeating fields, effectively allowing the embedding of tables within tables.
For example, a customer table may take the form of:
- id
- first_name
- last_name
- dob (date of birth)
- addresses(a nested and repeated field)
- addresses.status (current or previous)
- addresses.address
- addresses.city
- addresses.state
- addresses.zip
- addresses.numberOfYears (years at the address)
Image 2: Google BigQuery Nested / Repeated Fields Example
It’s easy to see how powerful these constructs can be at compressing information and reducing table joins, something that is anathema to the full table scan optimized cloud data warehouse platforms.
However, while these new constructs make data loading easier and querying faster, they add additional complexity for the consumer writing queries. Besides having to understand these more complex table constructs, each data platform has its own proprietary syntax for unnesting these data types.
A semantic layer can hide this additional complexity from the end user and abstract away the dialect differences of each platform. In this way, data warehouse architects can take advantage of these powerful new “schema on read” design principles without creating an additional burden on their data consumers.
5. It Drives Agility
So, with all these benefits of a semantic layer in a data fabric design, why is it still so costly, risky and time consuming for most enterprises to migrate their data and analytics operations to the cloud? The answer lies in a common and critical architectural mistake most enterprises committed years ago. By tightly binding their applications and tools to a particular data platform, these companies mortgaged their future flexibility and agility.
Reliance on platform specific stored procedures is a common barrier for data platform migration, but so is hard coding platform specific SQL dialects and SQL extensions into downstream applications and query tools. Even if you avoided these common pitfalls, coding applications and writing reports to a specific data schema is almost as bad. In each of these scenarios, agility and flexibility is compromised: any change in the base data platform layer cascades throughout the entire data stack creating cost and destroying agility.
So, why repeat the mistakes of the past when you have the opportunity to future proof your choices today for the unknowns of tomorrow? A semantic layer, coupled with data virtualization, abstracts the logical from the physical. By creating a semantic layer, downstream analytics consumers are protected from upstream changes in both technology and physical data architecture.
This separation of layers provides the foundation for making quick work at integrating new data sources and taking advantage of new data platform technologies with minimal end user disruption––all while ensuring your business is prepared for the changing world of tomorrow.
Next Steps
Through these examples, we can see how a semantic layer can power analytics self service by adding control, fidelity and simplification of enterprise data assets. Coupled with the other components in a data fabric design, the semantic layer serves as the source of business truth for the enterprise.
It’s clear that a semantic layer can help your company to map out your complex data into a clear and consolidated view. For organizations looking to get the most from their data, that clarity can make all the difference in finding their way ahead.

SHARE
Whitepaper | Enterprise Semantics for Power BI