Is it October already?
It’s hard to believe that October is here. It feels like only a few days ago that we released AtScale 5.0 and AtScale 5.5. Both releases contained a number of great new features that I was excited to share with the Big Data and Business Intelligence communities. Although I may be a little biased, I really do believe that the release of AtScale 6.0 marks one of the biggest releases in the history of the company. When Dave Mariani and the founding team created AtScale in 2013, we put in place a lofty mission for the company:

From day one, this simple vision has guided our architectural principles and engineering investments. AtScale was built from the ground up to support both traditional data types and formats (for example star schemas) as well as emerging “Big Data” types and formats, such as maps and arrays. We ensured that the AtScale Virtual Cube interface could speak the languages of Business Intelligence (BI) – SQL and MDX – so that business users can use their analysis tool of choice to drive business decisions. We invested significantly in technologies like AtScale’s Adaptive Cache™ to deliver interactive BI queries regardless of the size of the underlying data.
With the release of AtScale 6.0, we are making significant strides in realizing this vision. Keep reading to learn more about:
- Enhanced support for cloud deployments and databases.
- Significant performance and management improvements to AtScale’s Adaptive Cache.
- Major query planner, SQL, and MDX enhancements.
- Even more ways to connect your BI tools to AtScale.
- Enhanced data lineage tracking and column usage tracking
The future is cloudy, but Google BigQuery and AtScale shine
It’s no surprise that more and more data workloads are moving to the cloud. When we announced our plans earlier this year to expand our data platform support beyond Hadoop, the response from the market was overwhelmingly positive. With AtScale 6.0, we are thrilled to announce the General Availability of support for our first non-Hadoop platform, Google BigQuery. We’ve been keeping an eye on BigQuery for some time – our initial benchmarks were extremely positive, and we are seeing a rapid uptick in interest and adoption from both existing customers and new prospects. With AtScale 6.0, enterprises can now take advantage of AtScale’s universal semantic layer for BI directly on top of data sets that are stored in Google BigQuery.
__With AtScale 6.0, enterprises can now take advantage of AtScale’s universal semantic layer for BI directly on top of data sets that are stored in Google BigQuery. __
This integration provides a number of key benefits to current and future Google BigQuery customers looking to support Business Intelligence use cases:
- Provides the only way to directly execute live Microsoft Excel queries against BigQuery. Because AtScale supports the MDX query language and acts as an XMLA data provider, Excel users can create live pivot tables against virtually any data set, no matter how large, using AtScale and Google BigQuery.
- Supports interactive query response time for BI users, regardless of the underlying data size. With AtScale 6.0, BigQuery users can now take advantage of the Adaptive Cache – a system that continually analyzes query patterns and a creates multi-user, multi-attribute cache that can be used to satisfy a number of queries across the entire BI user base.
- AtScale also vastly reduces the cost of frequent query patterns. By re-routing BI user queries to the Adaptive Cache, the cost of each query (for the same result set) is greatly reduced. In initial testing with our beta customers we saw the cost for such queries decrease by 100X to 1,000X per query.
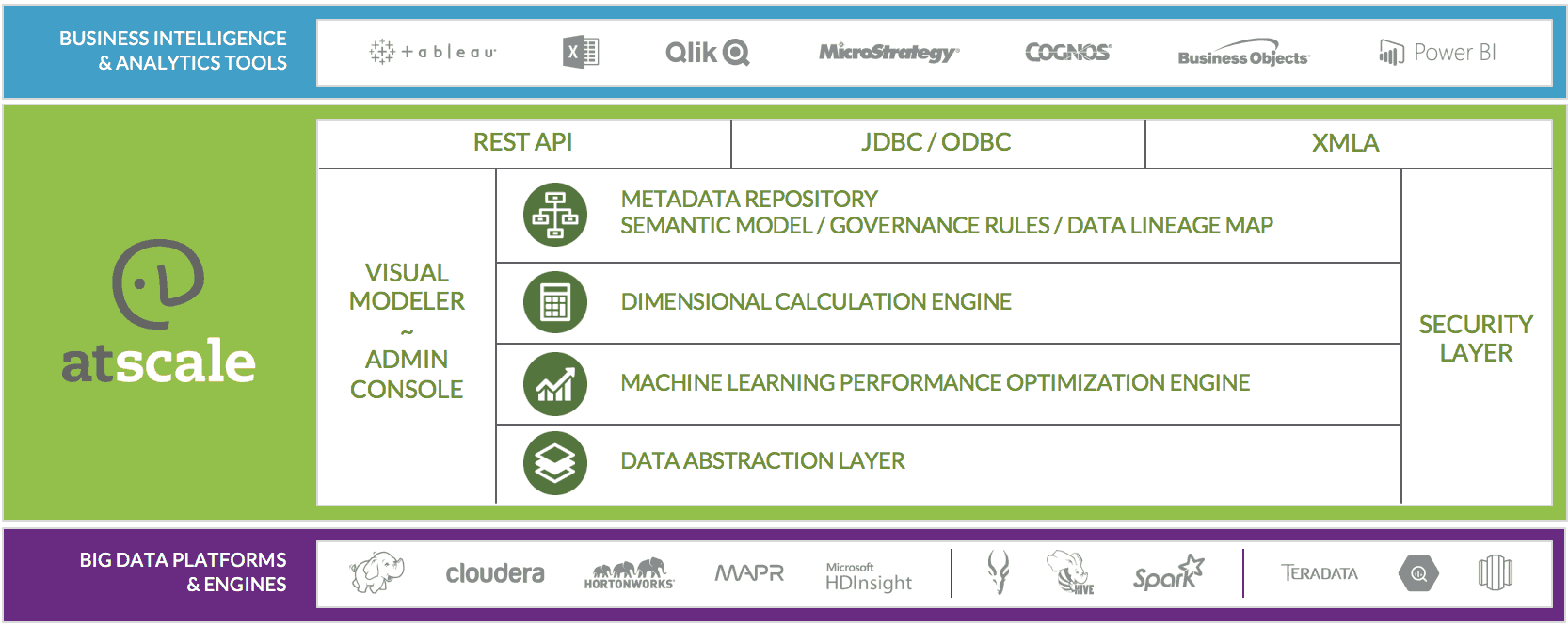
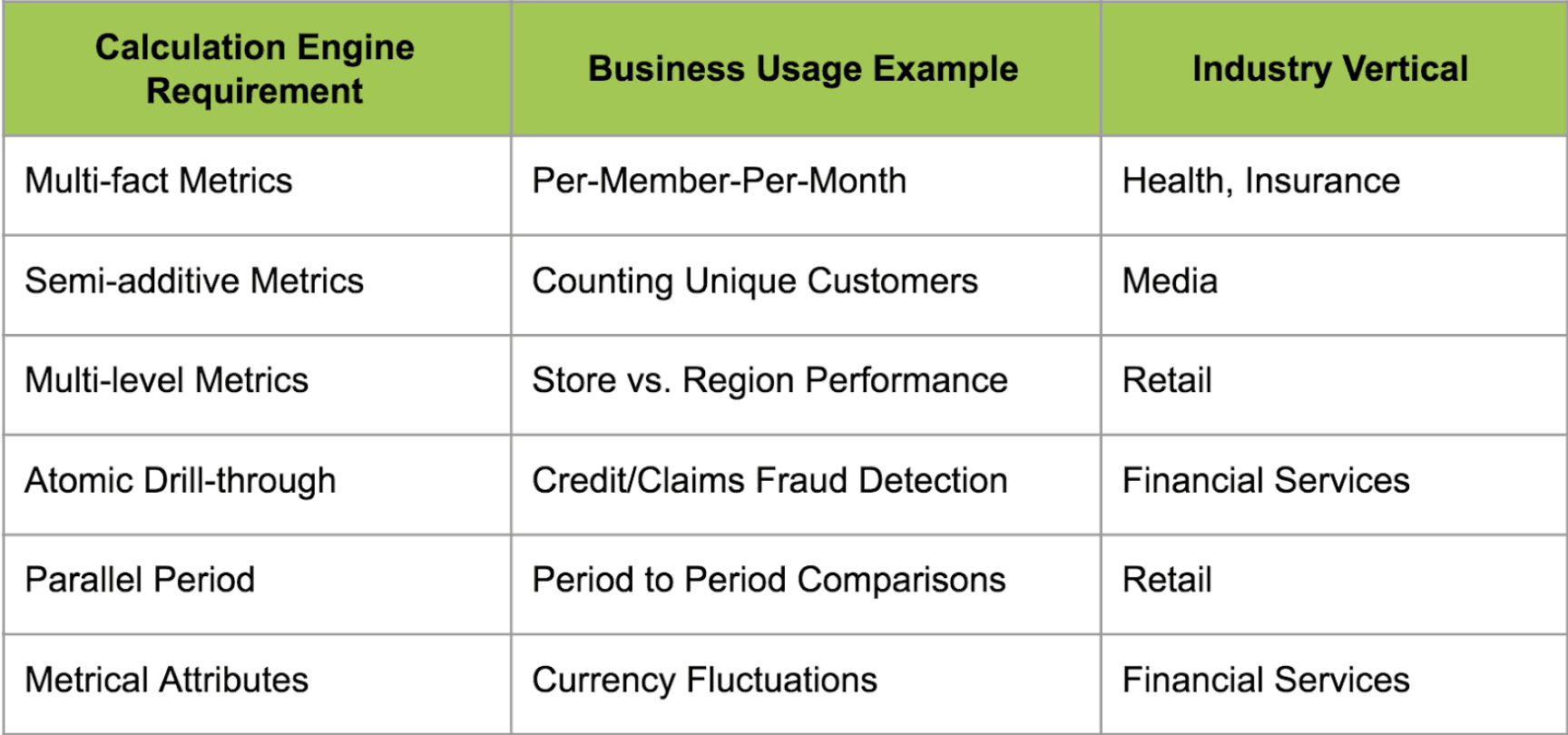
- AtScale 6.0 turns BigQuery into a scale-out OLAP server, with support for the types of complex models and business concepts that are demanded by Business Intelligence use cases. This means that users can use their tool of choice – Tableau, Excel, Microstrategy, Cognos, and more – against a shared semantic layer that represents core business concepts in a way that works for business users. Some typical examples of OLAP-style queries are shown in the table below.
On-premises and in the cloud, Hadoop rollouts continue
While serverless query approaches like BigQuery are showing a rapid uptick in adoption, Hadoop continues to be the standard for modern big data systems, and cloud adoption of Hadoop is on the rise.
Accelerated Data Structures – better, faster, stronger
With a large number of enterprise deployments under our belts, it’s fair to say that AtScale’s Adaptive Cache has been battle tested. We’ve taken these learnings and used them to dramatically enhance the performance and manageability of the system with the addition of several new features.
Local High-Speed Query Cache
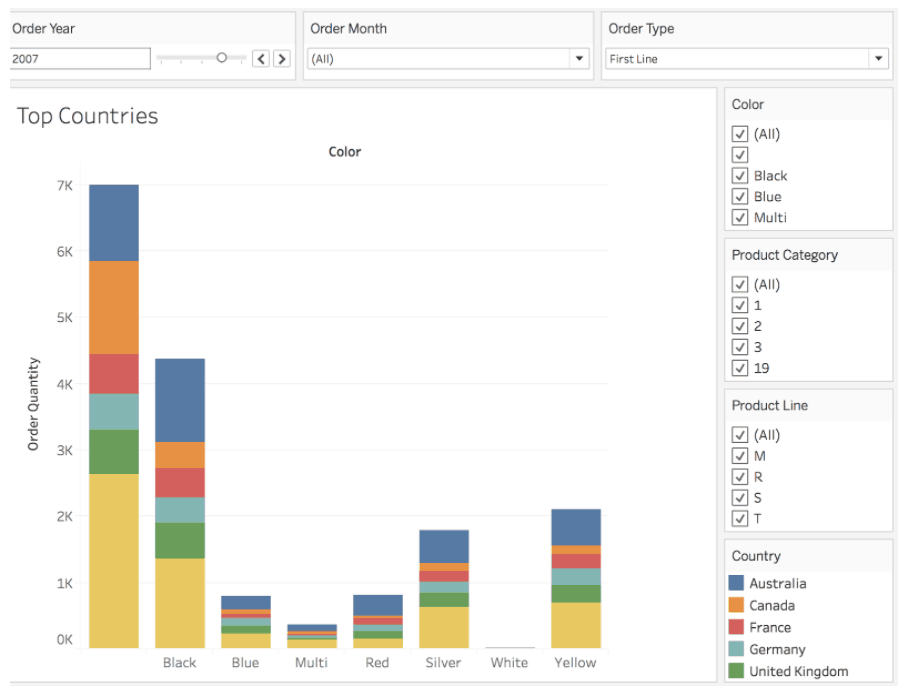
For enterprise BI use cases there are often a large number of repeating and predictable query patterns that are amenable to caching. For example, in this simple Tableau visualization there are 7 different filter lists that contain the distinct values for each filter set. Based on query telemetry from our installed base, we’ve seen that upwards of 65% of BI queries consist of such filter list queries. With AtScale 6.0, we now provide an option to create an AtScale-local cache that can be used to satisfy these queries. The result of this innovation is lightning fast dashboard and visualization rendering times, as well as, a significant reduction in query load and cost against the underlying big data platform.
Graph-Optimized Aggregate Sequencing
One of the core elements of the AtScale query engine is a graph-based, cost-optimization system that maintains an attribute graph of all potential data sources that can be used to satisfy a BI user’s query. These data sources include the underlying raw data, AtScale-managed aggregate tables, or locally cached data files. In AtScale 6.0, we’ve expanded the use of this graph engine so that we can optimally sequence the processing of the aggregates that make up the Adaptive Cache, starting with the finest grain aggregates first and then building more summarized aggregates later in the sequence. Our first deployments leveraging this capability have shown aggregate processing time improvements between 2X and 10X.
Aggregate Management Console
AtScale 6.0 also includes a significant number of UI improvements to make it easier for Administrators to manage and monitor the creation and subsequent maintenance of the accelerated data structures.
“Any Decision” means SQL and MDX for any BI tool
As AtScale adoption has grown, we’ve seen a broader and broader set of BI tools. While Tableau and Excel continue to be the most common, we see rapid adoption of PowerBI, as well as, a strong installed based of Qlik, Microstrategy, Cognos, and Business Objects. Each of these BI tools – through their own unique capabilities – generate a very wide range of SQL and MDX query constructs.
AtScale’s patented Hybrid Query Service allows virtually any BI tool – speaking either SQL or MDX – to get consistent and interactive query response time using the most widely adopted BI front-ends.
Request a Demo Now
With AtScale 6.0, we’ve made significant improvements to the range of supported constructs, including:
- Enhanced support for Tableau’s “Level of Detail” expressions.
- The addition of support for constraint-based measures.
- Enhanced MDX syntax support for queries generated by Cognos Report Studio and Microstrategy’s Advanced Analytics.
- Support for the PowerBI On-Premises Data Gateway in SQL mode.
All of these great enhancements mean that AtScale’s value as a single semantic layer forBI continues to grow for enterprises looking to scale BI for a diverse user base while maintaining a secure and well-governed interface to their big data platforms.
Data Modelers Love AtScale
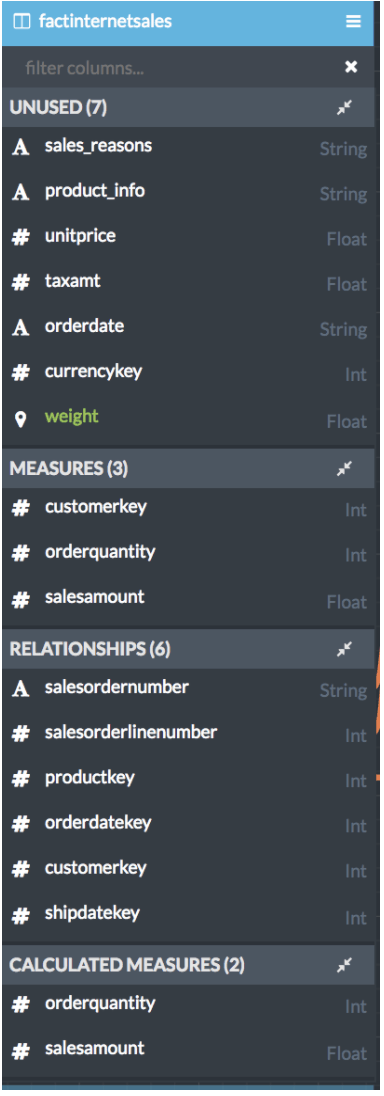
One of the consistent things I hear from AtScale users, especially those who have spent their careers building complex models in tools like Microstrategy Administrator or cubes in Microsoft Visual Studio, is how much they love the AtScale Virtual Cube design experience. We’ve invested heavily in making it easy and intuitive for users to quickly build, deploy, and access their AtScale data models. This investment never stops! AtScale 6.0 includes a number of great new features for cube designers, including:
- Supreme Commander View – allows users to easily organize and visualize models with a large number of data sets and dimensions.
- Relationship highlighting – by selecting an object on the canvas, users can now highlight related objects and easily focus on just the relationships that matter.
- Column usage tracking and categorization now allows designers to easily identify how and where data set columns are used, and focus in on only the columns that are relevant for a specific step in the cube design process.
Time to Get Started!
As you can tell, I am very excited about this release! It is a major step to realizing our company’s vision. With AtScale 6.0, our customers will immediately derive value from the capabilities above and will continue to benefit from the industry’s most robust and scalable business interface for big data!
I invite you to learn more about AtScale 6.0 today!
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics