When my co-founders and I launched AtScale almost ten years ago, we set out to democratize analytics consumption for everyone, not just database experts. We were dismayed to see the new generation of visualization tools forcing their users to become experts in data modeling and database technologies before they could do their job – answering questions about their business.
As we all know, ten years is a long time in the technology industry and things change. What hasn’t changed since we founded the company, though, is the desire to consume analytics where users live and breathe, whether that be Tableau, Power BI, Excel or even a data science notebook. Over the years, AtScale has helped organizations achieve their goal of data democratization by recognizing that the data model supporting an analytics semantic layer should be decoupled from the analytics tools used by data consumers. This allows users to leverage the tools they know and love while speaking the same language as others using different tools. The logical data models maintained in a universal semantic layer (sometimes I refer to these as semantic models) comprise this common language.
I am thrilled to announce a very important next step in AtScale’s evolution to address as broad an audience as possible. In this blog, I’ll dive into how AtScale is now democratizing semantic data modeling in addition to analytics consumption.
DataOps and The Rise of the Analytics Engineer
The role of the BI Engineer became a real job function in the early 1990s when the concept of the semantic layer was realized as a core function of enterprise BI platforms like Business Objects, Cognos and Microstrategy. The BI Engineer was a combination of business person and database expert – someone who knew how to express business concepts using database technology. As a data steward, the BI Engineer preferred to work with application GUIs to visually model data, not unlike the ETL tools of the day (i.e. Informatica) that provided a drag and drop interface to define transformation rules and data flows.
The BI Engineer role is still extremely important during this new analytics era built on the cloud-first, modern data stack. And AtScale stays committed to supporting this critical role in enterprise data teams. From the beginning, we sought to simplify the process of defining the semantic data model with an intuitive, visual modeling experience, designed for reusability and collaboration.
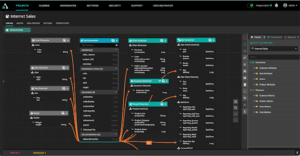
AtScale Design Center’s Visual Modeling Canvas
A visual modeling approach is ideal for the BI Engineer persona and makes the process of translating database objects into business-friendly terms simple and intuitive.
At the same time, the past few years have seen the rise of a new generation of code-first ETL/ELT tools from the likes of dbt Labs, and code-first data modeling from companies like Looker, Transform, and Cube. The Analytics Engineer has become a key player and a new persona for engineering data products. Leveraging DevOps concepts adopted from software engineering disciplines, the Analytics Engineer typically prefers to write code rather than using purpose-built applications.
In order to better serve this new Analytics Engineering persona, I am thrilled to announce AtScale Markup Language (AML).
With AML, AtScale is the first semantic layer platform to address both personas: the BI Engineer and the Analytics Engineer.
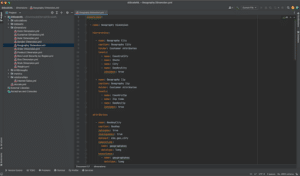
AtScale Markup Language (AML) as viewed in IntelliJ
With the addition of AML to the semantic data modeling toolbox, AtScale customers can now seamlessly move between code and a graphical user interface to create and share semantic data models. AML provides several benefits to accelerate the democratization of data within the enterprise that include:
- Promoting collaboration across business and engineering personas to expand and accelerate the semantic data modeling universe.
- Providing a common language for data stewards to share semantic data objects (i.e. conformed dimensions, calculations, etc.) and models across business domain teams.
- Enabling CI/CD integrated workflows using customers’ own DevOps processes using Git.
- Delivering a flexible API to promote integration with internal and external tooling.
Better yet, there are no compromises with AML. AtScale’s internal data model is based on AML, so moving between code and the AtScale modeling canvas is seamless. With almost ten years of semantic modeling maturity, AML developers can express all of the sophistication of the AtScale multidimensional engine – now, with code.
Integration-First for Semantic Data Modeling
If there was a single core philosophy or technical true north at AtScale, it would have to be our integration-first mindset. From the very beginning, we explicitly refused any attempt to “re-invent” the data visualization experience. Instead, we made sure to work with every consumption tool possible (Tableau, Power BI, Qlik, Excel, etc.) and integrate with them using their native interfaces rather than just forcing a SQL peg into a multi-dimensional (MDX/DAX) hole. We took the same approach with our integration with data platforms like Snowflake, Databricks, Google BigQuery, Redshift, and Azure Synapse. We also chose to be a good citizen in the data fabric universe by sharing our metadata with the enterprise data catalogs like Alation and Collibra, rather than invent our own.
So, when it came to creating a semantic layer markup language, we searched far and wide for an industry standard. While a few exist (i.e. LookML), none could express the richness of our multidimensional engine and semantic modeling capabilities. So, instead, we invented AML to provide our customers with a pure, 360 degree, bi-directional experience, compatible with our visual modeling tools.
But, recognizing the power of existing developer communities and following our commitment to our “integration-first” true-north, we will maintain open integration with other modeling approaches.
I am proud to announce that AtScale now supports dbt Metrics which is part of the dbt open source project supported by dbt Labs and their massive community.
Now, AtScale can seamlessly serve metrics defined as dbt Metrics referencing dbt Models directly from a Git repository. AtScale serves these metrics through live, optimized queries executed on any cloud data platform to common analytics consumption tools including Microsoft Excel and Power BI.
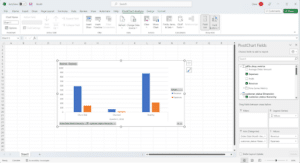
dbt Lab’s Jaffle Shop Metrics served by AtScale in an Excel Live Pivot Table
As you can see above, AtScale is serving dbt Labs’ Jaffle Shop Metrics sample project directly via the jaffle_shop_metrics Github repo in a live spreadsheet, using Microsoft Excel’s built-in Analysis Service connector and PivotTable service (no client-side software or add-ins needed).
Here’s the same Jaffle Shop Metrics model served by AtScale in Power BI:
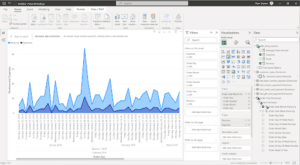
dbt Lab’s Jaffle Shop Metrics served by AtScale in a Live Power BI connection
AtScale’s well established integrations with common analytics tools can now serve dbt Metrics, providing customers with the ability to:
- Serve live queries for dbt Semantic Layer metrics.
- Connect with a wide range of data platforms today, including Snowflake, Databricks, Google BigQuery, Amazon Redshift, Azure Synapse, Postres, SQL Server and more.
- Query dbt Semantic Layer Metrics live with a wide range of consumption tools today, including Tableau, Power BI, Microsoft Excel, Google Looker, Qlik Sense, Jupyter Notebooks and more.
Supporting Data Mesh and Hub & Spoke
Software engineering is a discipline that requires collaboration with multiple teams. Building data products is no different. In order to enable the authoring of semantic data models across domains and teams, the same kind of DevOps workflows used by software development teams to collaborate are needed to support a semantic layer platform’s development as well.
From day one, AtScale has supported the sharing of semantic data modeling objects across teams using AtScale Design Center’s visual library. AML makes this model object sharing capability even easier by supporting the DevOps principles of version control, continuous integration and continuous deployment (CI/CD).
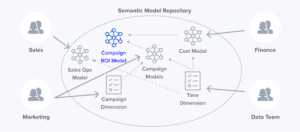
Semantic Model Object Sharing using AtScale
Now, customers can share semantic modeling objects as AML files in addition to leveraging the AtScale Design Center’s visual library. Whether you are a BI Engineer or a Analytics Engineer, teams can create their own libraries of shared modeling objects to speed semantic model development and drive consistency and governance.
With these new features in private preview for AtScale customers, we are excited to harness the passion and ingenuity of the code-first analytics engineering community to chart a new course toward semantic layer innovation. We believe that these new capabilities will turbocharge the adoption and proliferation of semantic data models by expanding the universe of data modelers to code-writing engineers. By combining the power of data stewardship with software engineering best practices, we believe that the semantic data model will become the thread that weaves our data fabric into a business interface that makes data accessible to everyone.
SHARE
WHITE PAPER