
Just this week, AtScale published the Q4 Edition of our BI-on-Hadoop Benchmark, and we found 1.5X to 4X performance improvements across SQL engines Hive, Spark, Impala and Presto for Business Intelligence and Analytic workloads on Hadoop.
Bottom line, the benchmark results are great news for any company looking to analyze their big data in Hadoop because you can now do so faster, on more data, for more users than ever before.
Setting the Stage
As some of you may recall from the Q1 ‘16 Edition, this benchmark takes an in-depth look at the performance of leading SQL-on-Hadoop engines and how well they perform on Business Intelligence (BI) and interactive analytics workloads.
In this Q4 ’16 Benchmark, not only did we test newer versions of the original engines tested in the Q1 Benchmark – Hive, Impala, and Spark – we also added Presto.
For those of you who aren’t familiar with how AtScale works, here’s a brief refresher:
- AtScale acts as a semantic layer that sits between your big data platform (for example Cloudera, Hortonworks, or MapR) and your favorite analytics and data visualization tools (like Tableau, Microsoft Excel, Qlik, MicroStrategy, Spotfire..etc).
- AtScale provides a dimensional interface on big data for these data visualization tools, combines the available SQL-on-Hadoop engines with our managed and optimized aggregate system in order to deliver an interactive BI experience.
- One ofAtScale’s core architecture principles is that it uses big data platforms for what they are good at: scale-out, large-volume data processing. As a result, we too are keenly interested in the performance of the SQL-on-Hadoop engines that we tested in the BI Benchmarks.
Testing Framework
When evaluating SQL-on-Hadoop engines and their fitness to satisfy Business Intelligence workloads we looked at three key areas of performance:
- Performs on Big Data: the SQL-on-Hadoop engine must be able to consistently analyze billions or trillions of rows of data without generating errors and with response times on the order of 10s or 100s of seconds.
- Fast on Small Data: the engine needs to deliver interactive performance on known query patterns and as such it is important that the SQL-on-Hadoop engine return results in no greater than a few seconds on small data sets (on the order of thousands or millions of rows).
- Stable for Many Users: the engine must be able to support concurrent queries issued by multiple users (10s, 100s and even 1000s of users) and perform reliably under highly concurrent analysis workloads.
Benchmark Ingredients
Below is a summary of the dataset, engines and other components involved in running this latest series of benchmark tests.
- Hadoop Cluster: 12 nodes. 1 master, 1 gateway, 10 worker nodes
- SQL-on-hadoop engines: Spark 2.0, Impala 2.6, Hive 2.1 with LLAP, Presto 0.152
- Data set: Based on the widely-used TPCH data set, modified to more accurately represent a data layout (in the form of a star schema) common for business intelligence workloads.
- Queries: 13 queries were tested to truly simulate a Business Intelligence enterprise environment. The queries used for this benchmark can be summarized into a several higher level query patterns, spanning from small dataset complexity to high data volume and sophistication.
- A real-bearded wizard: As with any good benchmark a genuine wizard of data needs to be involved, which in this case was our very own Trystan Leftwich, AtScale Sr. Engineer and Doer-of-all-things Technical.
Results of Large Query Performance
Consistent with the findings in the Q1 ‘16 Edition of the BI on Hadoop Benchmarks, the Q4 ’16 Benchmark found the following result for Big Data (6 billion rows).
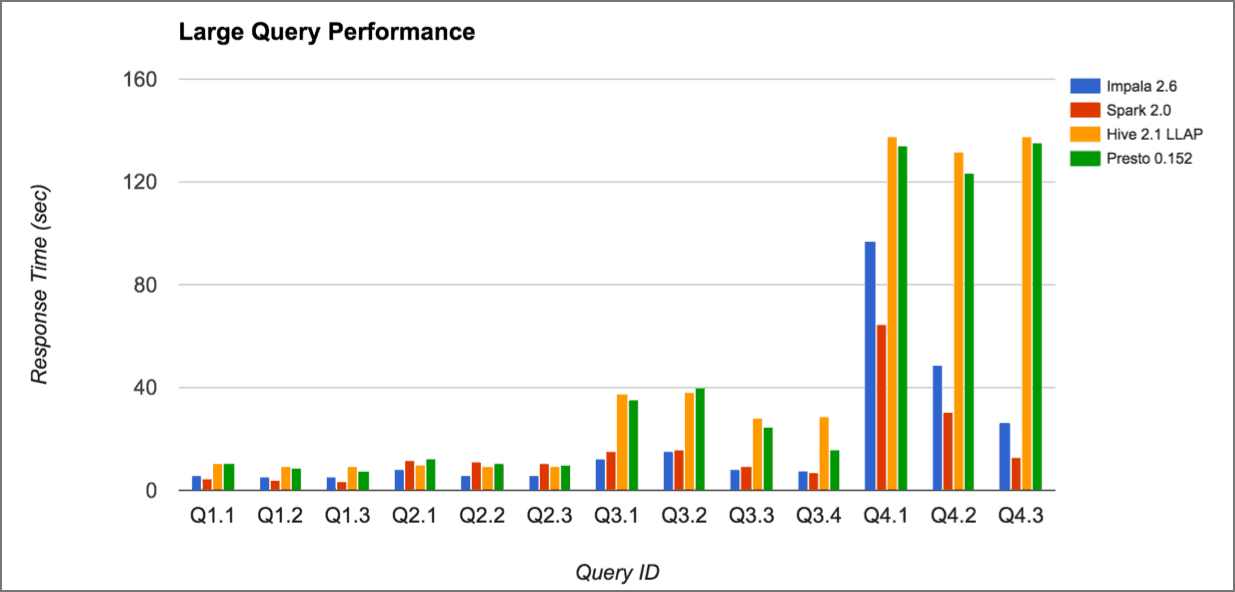
- Spark SQL and Impala tend to be faster than Hive.
- For many queries, the performance difference between Impala and Spark SQL is relatively small.
- Presto 0.152, a newcomer to the Second Edition of the BI on Hadoop Benchmarks, shows a performance profile that is very similar to that of Hive 2.1
Results of Small Query Performance
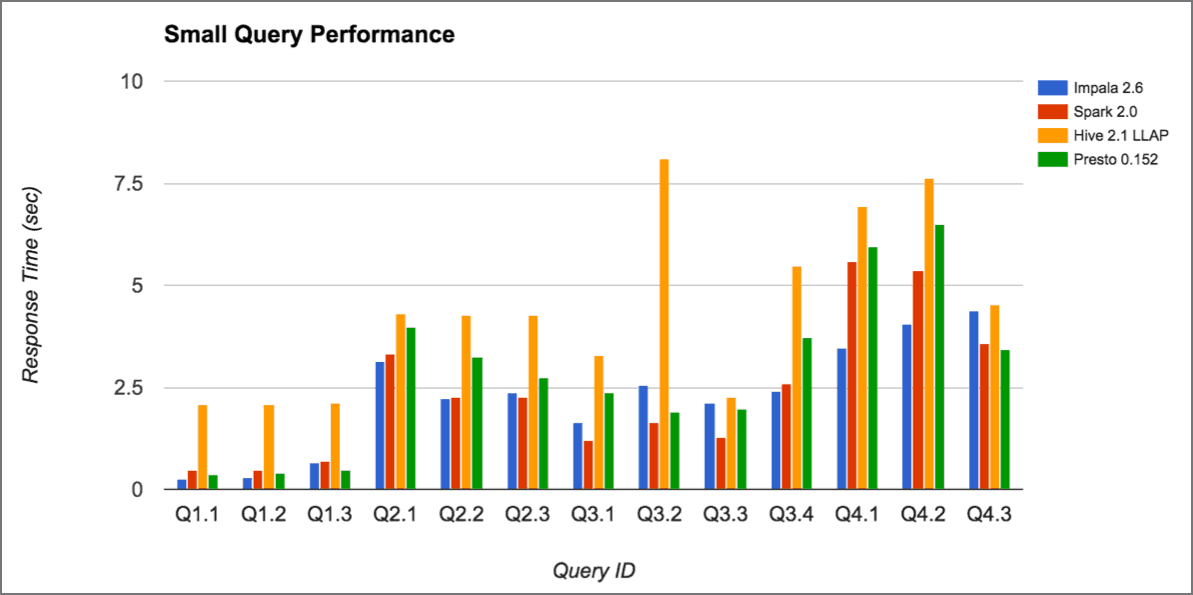
On “small queries” our benchmark results also illustrate significant performance gains that can be realized from leveraging aggregates , with query performance for the same query improving by as much as 50X.
In real-life deployments on larger data sets (on the order of 100s of Billions of rows) AtScale customers have seen performance gains over 100-200X as a result of this technology.
Results of Concurrent Query Performance
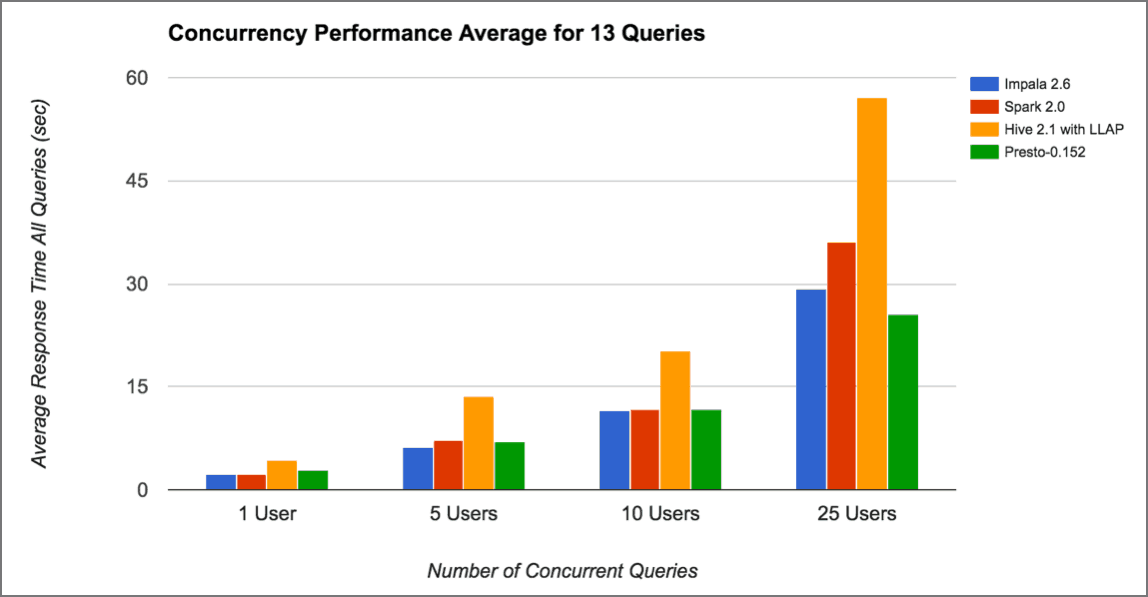
While all engines were able to scale to support up to 25+ concurrent users, we did observe different behaviors from the various engines tested.
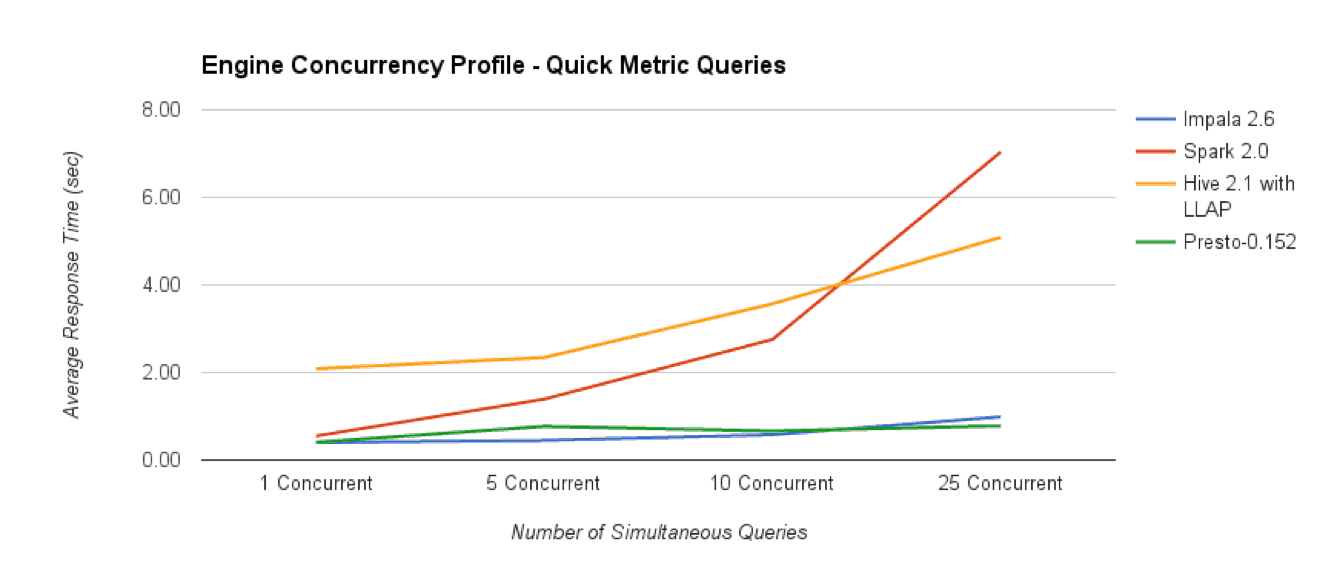
- Impala’s performance scaled better than Spark SQL or Hive as the number of concurrent users increased these results are consistent with AtScale’s experience using Impala in real-world customer deployments.
- Presto’s MPP architecture also delivers excellent concurrent query scaling results, showing virtually no degradation with up to 25 concurrent Quick Metric queries.
- It is worth noting that both Presto and Impala were able to satisfy the 25 concurrent user workload and maintain an average query response time of under 1 second.
Performance Gains Version-to-Version
When it comes to performance gains our benchmark also showed AtScale’s use of SQL-on-Hadoop engines is also yielding great dividends for all.
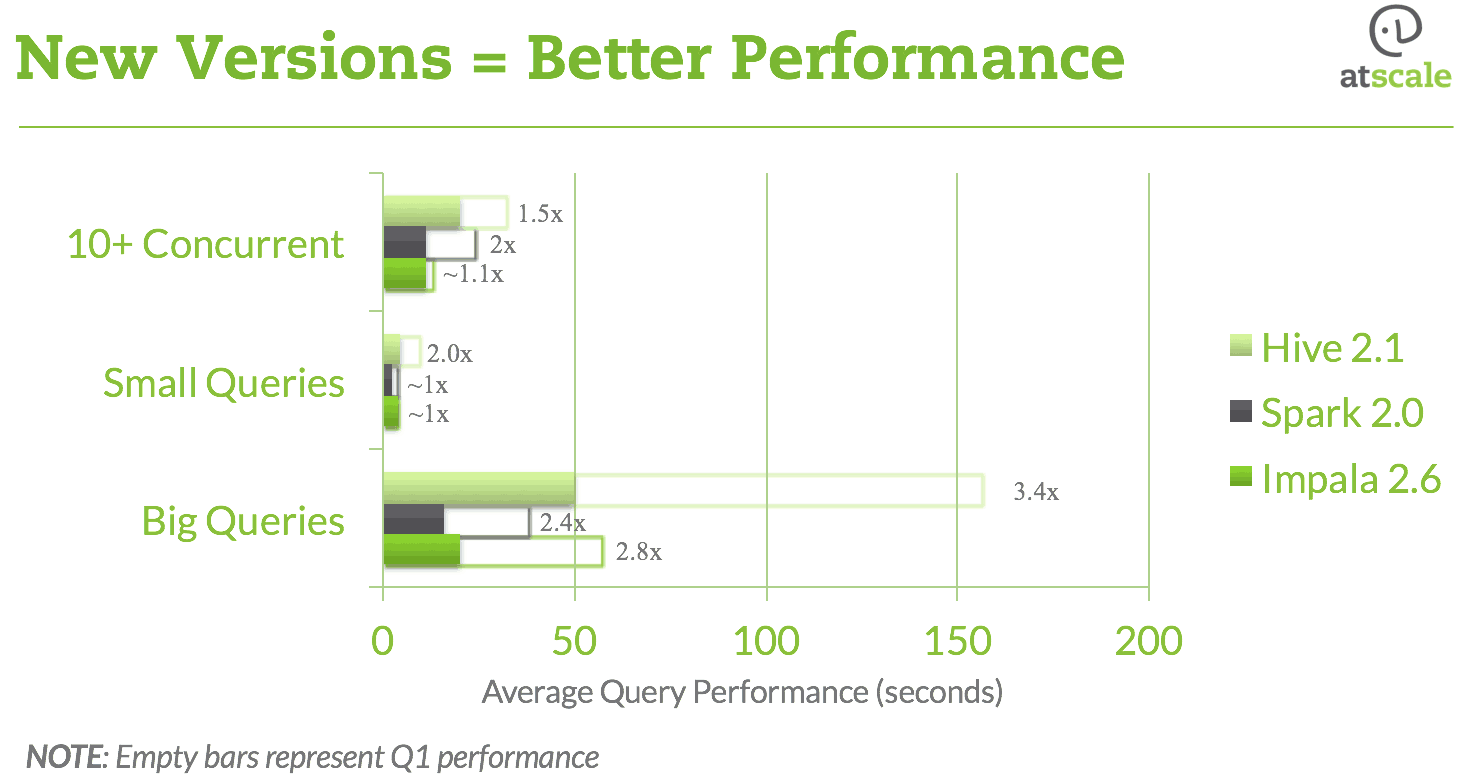
As shown in the chart above, we saw performance gains of between 200% to 400% across all of the engines tested between the Q1 2016 and Q4 2016 Benchmark editions.
These gains were achieved as a result of the significant community investments that have gone into Hive, Spark, and Impala over the past six months.
The results of this benchmark are great news for everyone in the Hadoop and BI on Hadoop ecosystem (customer, developer, and vendor alike).
Summary of Key Findings
In summary, we found this Benchmark study to reveal the following insightful and good news regarding the current state of SQL-on-Hadoop engines and their support of Business Intelligence workloads:
- In the SQL-on-Hadoop wars, everyone wins: We saw significant improvements between the First and Second Editions of the benchmark, on the order of 2x to 4x, in the six months between each round of testing. This is great news for those enterprises deploying BI workloads to Hadoop.
- There is no single “best engine”: With the release of Hive’s LLAP technology the differences between Hive and other persistent query engines (Spark SQL, Impala, Presto) has decreased significantly. While Impala and Spark SQL continue to shine for small data queries (queries against the AtScale Adaptive Cache), Hive now delivers suitable “small data” query response times as well. Presto also shows promise on small, interactive queries.
- Small vs. Big Data differences are diminishing: Presto, Hive, Impala, and Spark SQL were all able to effectively complete a range of queries on over 6 Billion rows of data. The “winning” engine for each of our benchmark queries was dependent on the query characteristics (join size, selectivity, group-bys).
- Presto and Impala scale best for concurrent dashboard queries: With production enterprise BI user-bases on the order of 100s or 1,000s of users, support for concurrent query workloads is critical. Our benchmarks showed that Presto and Impala performed best (showed the least query degradation) as concurrent “Quick Metric” query workload increased.
- All engines are suited to handle large user bases that generate mixed workloads: All engines showed linear, non-breaking performance degradation for larger analytic-style query workloads.
- A successful BI on Hadoop architecture will likely require more than one engine: Every SQL-on-Hadoop engine has its strengths: Presto’s and Impala’s concurrency scaling support for quick metric queries, Spark SQL’s handling of large joins, Hive’s and Impala’s consistency across multiple query types. Enterprises might consider leveraging different engines for different query patterns, and providing an abstraction-based BI layer, such as AtScale, to automatically route queries to the best query engine for the job without additional work required by, or noticed, on the client application side.
We hope these results prove interesting and helpful! Let us know what you think, and what you’d like to see in our next run of the Benchmark in 2017.
SHARE
Guide: How to Choose a Semantic Layer