April 6, 2026
Best Data Governance Tools for Enterprises: 2026 GuideDefinition of a Cloud Data Warehouse
A Cloud Data Warehouse is a database of highly structured, ready-to-query data managed in a public cloud. Typically, cloud data warehouses represent the following features:
- Massively parallel processing (MPP): Cloud-based data warehouses typically support big data use cases and apply MPP architectures to provide high-performance queries on large data volumes. MPP architectures consist of many servers running in parallel to distribute processing and manage multiple input/output (I/O) loads.
- Columnar data stores: MPP data warehouses are typically columnar stores — which are typically the most flexible and economical for doing insights and analytics. Columnar databases store and process data by columns instead of rows and make aggregate queries, the type often used for reporting, run dramatically faster.
Purpose
The purpose of cloud data warehousing is to realize the benefits of modern cloud architectures that typically combine the scale and availability of data warehousing, the flexibility of big data platforms and the elasticity of the cloud at a fraction of the cost of traditional solutions.
Typical benefits of cloud data warehouses are as follows:
Faster Speed-to-Insights – A cloud data warehouse provides more powerful computing capabilities, and will deliver real-time cloud analytics using data from diverse data sources much faster than an on-premises data warehouse, allowing business users to access better insights, faster.
Scalability – A cloud-based data warehouse offers immediate and nearly unlimited storage, and it’s easy to scale as needs expand. Increasing cloud storage doesn’t require the purchase of new hardware as an on-premises data warehouse does, so cloud data warehouses typically cost a fraction of an on-premise cost.
Overhead – Maintaining a data warehouse on-premises requires a dedicated server room full of expensive hardware, and experienced employees to operate, manually upgrade, and troubleshoot issues. A cloud data warehouse requires no physical hardware or allocated office space, making operational costs significantly lower.
Cloud data warehouses also offer additional benefits such as automation to improve speed, scale and flexibility. Further, applying a model-driven approach, including utilizing tools such as a semantic layer and data catalogs will make the process of finding data and creating data products more effective and efficient, supporting federalization of insights creation supported by centralized infrastructure, tools and governance. These additional capabilities and benefits are highlighted below:
- Real-time data ingestion and updates – simple, universal solution for continuously ingesting enterprise data into the cloud-based data warehouses in real time.
- Automated workflow – model-driven approach to continually creating, sharing and refining data products and managing data warehouse operations.
- Trusted, analysis-ready data – fully structured, integrated, dimensionalized analysis-read data with reliable data management and governance tools, including semantic layer and data catalogs to improve data access, sharing and refinement.
Primary Uses of a Cloud Data Warehouse
Cloud data warehouses are used to provide highly structured, integrated, dimensionalized analysis and analytics-use ready data to insights creators and consumers. Cloud data warehouses provide all of the benefits of an on-premise data warehouse with the extra benefits of being managed in a public cloud. These additional benefits include the following: faster speed-to-insights, scalability, flexibility, automation at a lower cost, both for infrastructure as well as operational management, including compute, storage and network costs. Cloud data warehouse software (databases) provide the power, scale and flexibility to handle the variety, velocity and volume of data sources, ideally with minimal manual coding and maintenance.
A complete set of services support Cloud Data Warehouse include a data storage layer (databases), compute layer or query processing layer and a cloud services layer as depicted below:
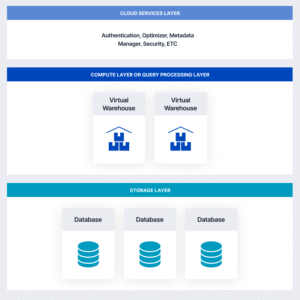
Benefits of a Well-Executed Cloud Data Warehouse
The benefits of using a cloud data warehouse to deliver highly structured, integrated dimensionalized data that is available for querying, analysis and analytics are listed below:
- Speed – Insights created from cloud data warehouses enable actions to be taken faster, because the insights are structured to address business questions more timely and effectively.
- Scale – Cloud data warehouses support an ever increasing number of data sources, users and uses that are also increasingly diverse across functions, geographies and organizations.
- Cost Effectiveness – With more data, comes more cost for data storage, compute and resources to manage. Cloud data warehouses are designed to ensure that costs are minimized by focusing on providing consistent, effective shared infrastructure with tools and processes that are automated, low code / no code self-service oriented and reusable with minimal resources and hand-offs.
- Flexible – Cloud data warehouses should be capable of addressing the myriad options impacting data source types, including volume, variety and velocity.
Cloud Data Warehouse Capabilities
Each of the major public cloud vendors offer their own flavor of a cloud data warehouse service: Google offers BigQuery, Amazon has Redshift and Microsoft has Azure SQL Data Warehouse. There are also cloud offerings from the likes of Snowflake that provide the same capabilities via a service that runs on the public cloud but is managed independently. For each of these services, the cloud vendor or data warehouse provider delivers the following capabilities “out of the box”:
-
- Data storage and management: data is stored in a cloud-based file system (i.e. S3).
- Automatic upgrades: there’s no concept of a “version” or software upgrade.
- Capacity management: it’s easy to expand (or contract) your data footprint.
Common Roles and Responsibilities – Cloud Data Warehouse Users
Cloud data warehouses, including the resulting creation of highly structured, dimensionalized data products and subsequent actionable insights delivered to business users involves the following key roles:
- Data Engineers – Data engineers create and manage data pipelines that transport data from source to target, including creating and managing data transformations to ensure data arrives ready for analysis.
- Analytics Engineers – Analytics engineers support data scientists and other predictive and prescriptive analytics use cases, focusing on managing the entire data to model ops process, including data access, transformation, integration, DBMS management, BI and AI data ops and model ops.
- Data Modelers – Data Modelers are responsible for each type of data model: conceptual, logical and physical. Data Modelers may also be involved with defining specifications for data transformation and loading.
- Technical Architect – The technical architect is responsible for logical and physical technical infrastructure and tools. The technical architect works to ensure the data model and databases, including source and target data is physically able to be accessed, queried and analyzed by the various OLAP tools.
- Data Analyst / Business Analyst – Often a business analyst or more recently, data analyst are responsible for defining the uses and use cases of the data, as well as providing design input to data structure, particularly metrics, topical and semantic definitions, business questions / queries and outputs (reports and analyses) intended to be performed and improved. Responsibilities also include owning the roadmap for how data is going to be enhanced to address additional business questions and existing insights gaps.
Key Business Processes Associated with Cloud Data Warehouse
The processes for delivering data and insights from a cloud data warehouse include the following:
- Access – Data, often in structured ready-to-analyze form and is made available securely and available to approved users, including insights creators and enablers.
- Profiling – Data are reviewed for relevance, completeness and accuracy by data creators and enablers. Profiling can and should occur for individual datasets and integrated data sets, both in raw form as was a ready-to-analyze structured form.
- Modeling – Creating logical and physical data models to integrate, structure, dimensionalize and semantically organize data for ready-to-analyze use.
- Extraction / Aggregation – The integrated dataset is made available for querying, including, including aggregated to optimize query performance.
Common Technologies Categories Associated with Cloud Data Warehouse
Technologies involved with a cloud data warehouse are as follows:
- Data Engineering – Data engineering is the process and technology required to move data securely from source to target in a way that it is easily available and accessible.
- Database – Databases store data for easy access, profiling, structuring and querying. Databases come in many forms to store many types of data.
- Data Warehouse – Data warehouses store data that are used frequently and extensively by the business for reporting and analysis. Data warehouses are constructed to store the data in a way that is integrated, secure and easily accessible for standard and ad-hoc queries for many users.
- Data Lake – Data lakes are centralized data storage facilities that automate and standardize the process for acquiring data, storing it and making it available for profiling, preparation, data modeling, analysis and reporting / publishing. Data lakes are often created using cloud technology, which makes data storage very inexpensive, flexible and elastic.
Trends / Outlook for Cloud Data Warehouses
Key trends to watch in the Cloud Data Warehouse arena are as follows:
Semantic Layer – The semantic layer is a common, consistent representation of the data used for business intelligence used for reporting and analysis, as well as for analytics. The semantic layer is important, because it creates a common consistent way to define data in multidimensional form to ensure that queries made from and across multiple applications, including multiple business intelligence tools, can be done through one common definition, rather than having to create the data models and definitions within each tool, thus ensuring consistency and efficiency, including cost savings as well as the opportunity to improve query speed / performance.
Real-Time Data Ingestion and Streaming (CDC) – Create and manage data as live streams to enable and support modern cloud-based analytics and microservices.
Extend enterprise data into live streams to enable modern analytics and microservices with a simple, real-time and universal solution.
Data Governance – Implementing effective, centrally managed data governance, including data usage policies, procedures, risk assessment, compliance and tools for managing secure access and usage such as semantic layer, metric stores, feature stores and data catalogs.
Agile Data Warehouse Automation – Quickly design, build, deploy and manage cloud data warehouses without manual coding.
Managed Data Lake Creation – Automate complex ingestion and transformation processes to provide continuously updated and analytics-ready data lakes.
Automation – Increase emphasis is being placed by vendors on ease of use and automation to increase speed-to-insights. This includes offering “drag and drop” interfaces to execute data-related preparation activities and insights creation / queries without having to write code, including reusing activities and processes, both for repeating use as well as sharing.
Self-service – As data grows, availability of qualified data technologists and analytics are very limited. To address this gap and increase productivity without having to lean 100% on IT resources to make data and analysis available, Self-service is increasingly available for data profiling, mining, preparation, reporting and analysis. In addition tools like the Semantic Layer offered by AtScale, Inc are also focused on enabling business users / data analysts to model data for business intelligence and analytics uses.
Transferable – Increased effort is also underway to make data easier to consume, and this includes making data available for publishing easier, including using api’s and via objects that store elements of the insights.
Observable – Recently, a host of new vendors are offering services referred to as “data observability”. Data observability is the practice of monitoring the data to understand how it is changing and being consumed. This trend, often called “dataops” closely mirrors the trend in software development called “devops” to track how applications are performing and being used to understand, anticipate and address performance gaps and improve areas proactively vs reactively.
Factors to Consider When Choosing a Cloud Data Warehouse
How these cloud data warehouse vendors deliver these capabilities and how they charge for them is where things get more nuanced. Let’s dive deeper into the different deployment implementations and pricing models.
Cloud Architecture: Cluster versus Serverless
There are two main camps of cloud data warehouse architectures. The first, older deployment architecture is cluster-based: Amazon Redshift and Azure SQL Data Warehouse fall into this category. Typically, clustered cloud data warehouses are really just clustered Postgres derivatives, ported to run as a service in the cloud. The other flavor, serverless, is more modern and counts Google BigQuery and Snowflake as examples. Essentially, serverless cloud data warehouses make the database cluster “invisible” or shared across many clients. Each architecture has their pros and cons (see below).
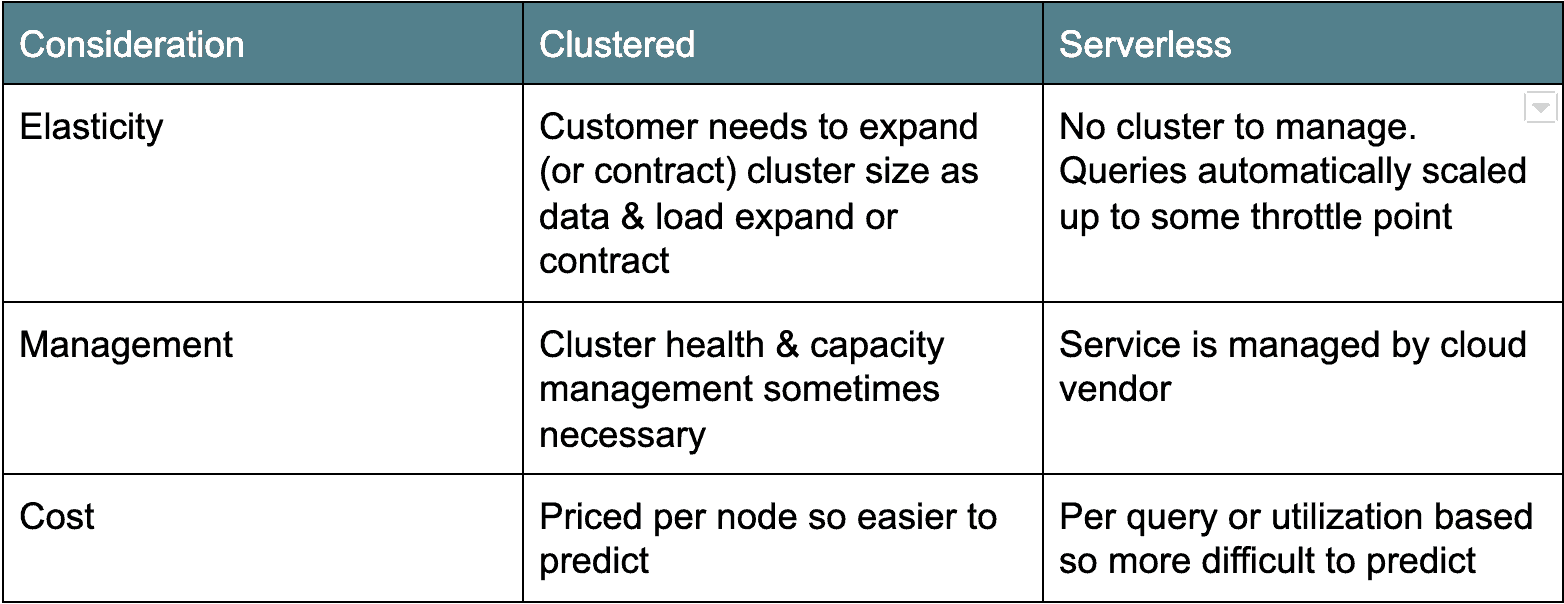
Cloud Data Pricing: Pay by the Drink or by the Server
Besides deployment architecture, another major difference between the cloud data warehouse options is pricing. In all cases, you pay some nominal fee for the amount of data stored. But the pricing differs for compute.
For example, Google BigQuery and Snowflake offer on-demand pricing options based on the amount of data scanned or compute time used. Amazon Redshift and Azure SQL Data Warehouse offer resource pricing based on the number or types of nodes in the cluster. There are pros and cons to both types of pricing models. The on-demand models only charge you for what you use which can make budgeting difficult as it is hard to predict the number of users and the number and size of the queries they will be running. I know one customer example where a user mistakenly ran a $1,000+ query.
For the node based models (i.e. Amazon Redshift and Azure SQL Data Warehouse), you pay by the server and/or server type. This pricing model is obviously more predictable but it’s “always on” so you are paying a flat price regardless of usage.
Pricing is a major consideration and requires a great deal of use case and workload modeling to find the right fit for your organization.
Challenges and Considerations for Cloud Migration (the “Gotchas”)
At AtScale, we’ve seen lots of enterprises attempt a migration from their on-premise data lakes and/or relational data warehouses to the cloud. For many, their migrations “stall” after the first pilot project due to the following reasons:
- Disruption: downstream users (business analysts, data scientists) have to change their habits and re-tool their reports and dashboards.
- Performance: the cloud data warehouse doesn’t match the performance of highly tuned, legacy on-premise data platforms.
- Sticker shock: unanticipated or unplanned operating costs and lack of cost controls.
AtScale and Cloud Data Warehousing
AtScale is the leading provider of the Semantic Layer – to enable actionable insights and analytics to be delivered with increased speed, scale and cost effectiveness. Research confirms that companies that use a semantic layer improve their speed to insights by 4x – meaning that a typical project to launch a new data source with analysis and reporting capabilities taking 4 months can now be done in just one month using a semantic layer.
AtScale’s semantic layer is uniquely positioned to support rapid, effective use of cloud data warehouses: AtScale provides the ability to ensure that data used for AI and BI are consistently defined and structured using common attributes, metrics and features in dimensional form, including automating the process of data inspection, cleansing, editing and refining as well as rapidly adding additional attributes, hierarchies, metrics / features, and extracting / delivering ready-to-analyze data automatically for multiple BI tools, including Tableau, Power BI and Excel. Moreover, this work only requires one resource who understands the data and how it is to be analyzed, eliminating the need for complexity and resource intensity. This approach to data operations automation eliminates multiple data hand-offs, manual coding, the risk of duplicate extracts and suboptimal query performance.
SHARE
Guide: How to Choose a Semantic Layer