The purpose of this blog is to introduce the modern data landscape. We want to provide our perspective on the data and analytics industry — where we’ve been, where we are now, and where we are heading. We’ll also discuss the catalysts for improvement to the data and analytics capabilities being sought, the vendors providing them, and the investments that are being made.
The emphasis will be on the purpose and direction of the modern data landscape, with a focus on the fundamental need for actionable, impactful insights and analytics that are delivered with speed, scale, and cost effectiveness. The rise of the semantic layer will be featured, including new research that affirms the value of using a semantic layer to deliver increased speed, scale, and success for AI and BI.
Catalysts for Change
It’s hard to believe that just 15 years ago, big data and cloud technology emerged with the introduction of Hadoop and cloud vendor offerings. Over the past five years, most enterprises have moved to the cloud, motivated by the dual need for digital transformation of their business, coupled with embracing cloud-based data platforms and tools to realize the benefits of advanced insights and analytics. Most companies have now migrated to the cloud, with most if not all their data available in a cloud-based data lake.
Also, given the ever-increasing number of success stories across a wide variety of industries, companies have bought in to using data and analytics to significantly improve business performance, with many implementing an initial set of use cases and making plans for continued expansion.
The resulting investment in big data technology reveals the scope of this transformation: according to research firm International Data Corporation (IDC), worldwide spending on big data and business analytics (BDA) solutions in 2021 was forecast to reach $215.7 billion, an increase of 10.1% over 2020 — with IDC forecasting that BDA spending will gain strength over the next five years as the global economy recovers from the COVID-19 pandemic. The compound annual growth rate (CAGR) for global BDA spending over the 2021-2025 forecast period will be 12.8%, much larger than most every category of IT spend. Per IDC, total BDA spend is expected to be split evenly between services and software solutions.
Defining the Modern Data Landscape
Let’s define the modern data landscape. We will also take a look at the areas that are rapidly emerging, including those most suited to support increased speed, scale, and cost savings for AI and BI.
Modern Data Landscape: Capability Areas
The modern data landscape consists of seven major capability areas, representing 15 individual capability components. Let’s briefly review each of the capability areas:
1. Raw Data – Raw data represent sources and storage of raw data sources. There are two major categories of raw data:
- Data Lakes offered by cloud providers
- SaaS applications where data is managed by the vendor for clients, who can access it via web protocols, including APIs.
2. Data Preparation, Integration, Workflow (DPIW) – The DPIW capability area enables data to be extracted and prepared, which involves cleaning and transforming the data, and making it available as a ready-to-use set of data. There are two major categories of DPIW:
- Data Transformation and Preparation Tools – These are tools to profile the data, assess it, cleanse it, and transform it to make it ready for analysis, including as a single data source or integrated with other prepared data sources. Often, these tools create data pipelines and automate the process of data preparation.
- Customer Data Platforms / Event Tracking – With the increased maturity and confluence of e-commerce and digital marketing, companies now must use a plethora of data sources and vendors to manage customer data across a myriad of channels. As a result, Customer Data Platforms, which offer purpose-built capabilities to manage customer identification, hygiene, as well as rapid access and integration of data between multiple marketing data vendors and channels, have increased exponentially in popularity.
3. Data API – The Data API Layer is rapidly emerging as another accelerator for companies to more rapidly access data from source systems, including data warehouses in the cloud and process it at the source (rather than move it). There are three major categories of Data API vendors:
- Cloud Data Warehouse – A cloud data warehouse is a database stored as a managed service in a public cloud and optimized for scalable BI and analytics. Cloud data warehouses typically offer three major services: secure access, compute or query processing, and storage.
- Data Lake Engines – A data lake engine is an open source software solution or cloud service that provides critical capabilities for a wide range of data sources for analytical workloads through a unified set of APIs and data model. Data lake engines address key needs in terms of simplifying access, accelerating analytical processing, securing and masking data, curating datasets, and providing a unified catalog of data across all sources. Data lake engines simplify these challenges by allowing companies to leave data where it is already managed, and to provide fast access for data consumers, regardless of the tool they use.
- SaaS APIs – These providers offer rapid, software-as-a-service (SaaS) data integration service for companies to extract, load, and transform (ELT) data from different sources into data warehouses. Often these providers create a standardized data model and framework to move data from standardized sources, including other SaaS-based data providers and sources.
4. Logical Data Models – This capability is critical to ensuring that data are consistently available to the consumption layer for AI and BI applications. There are three major categories of Logical Data Model providers:
- Semantic Layer – The semantic layer improves the time to insights for AI and BI by simplifying, automating, standardizing, and optimizing how data products are created, consumed, and queried for AI and BI. Semantic layer leaders like AtScale offer a comprehensive set of capability components, including consumption integration, semantic modeling, data preparation virtualization, multi-dimensional calculation engine, performance optimization, analytics governance, and data integration.
- Metric and Feature Stores – Another fast-growing area within the data landscape is the use of metric and feature stores. Metric stores are typically used to support business intelligence whereas feature stores support data science uses. Both metric stores and feature stores address common needs and benefits. Namely, to support the consistent definition of metrics and features, and provide a single, centralized source for consistent reuse across the enterprise.
- Data Virtualization – Data virtualization provides a logical data layer that enables access and integration of data sources (often across disparate systems), manages the unified data for centralized security and governance, and delivers it to business users without having to physically move the data. Data virtualization is often used in conjunction with a semantic layer, where data virtualization accelerates access to the source data whereas the semantic layer accelerates the ability to access the integrated (often from multiple sources), analysis-ready data (and refine it) for consumption consistently by multiple AI and BI tools.
- Data Governance – Data governance (DG) is the process of managing the availability, usability, integrity, and security of the data in enterprise systems, based on internal data standards and policies that also control data usage. As the number of data sources, users, uses, and consumption tools increase for both the data, but also the data products (refined data sets created by the semantic layer models and metric or feature stores), data governance becomes increasingly important. Please note that companies like AtScale provide governance capabilities built into the semantic layer to govern data as a product.
5. Data Consumption – This capability is critical to ensuring that data is structured and presented effectively for business intelligence as well as analytics. There are two major categories of data consumption vendors:
- BI Tools – BI tools are types of application software that collect and process large amounts of data from internal and external systems. BI tools provide a way of amassing data to find information primarily through queries delivered via reports, dashboards, and data visualizations.
- AI andML Tools – These are tools designed to speed up the process of creating AI and ML models. Often they offer workflow automation, data preparation, access to models / algorithms, and support training and operationalization.
6. Data Catalogs – A data catalog is an organized inventory of data assets available for access within the enterprise. Data Catalogs use metadata to help organizations manage access to their data, including collecting, organizing, accessing, and enriching metadata to support data discovery and governance.
7. Data Observability – Rapidly emerging within the modern data landscape, Data Observability refers to an organization’s ability to fully understand the health and reliability of the data in their system. Continuous monitoring of data to determine if changes are taking place is critical. This includes ensuring that all data sourced, created, transformed, synthesized, summarized, and consumed are consistently defined and delivered as needed to support multiple applications.
Modern Data Landscape – Capability Areas and Vendors

Where Do We Go From Here? The Need for Speed, Scale, and Cost Effectiveness
What’s driving the evolution of the modern data landscape? Fundamentally, we use data to answer business questions, and what businesses need are actionable insights and analytics. More importantly, these insights need to be delivered with speed, scale, governance, and cost-effectiveness.
Capabilities and vendors that can deliver actionable insights faster via automation, self-service, and a hub-and-spoke delivery model, can achieve scale in terms of data sources, users, and usage. This helps organizations manage costs via cloud-based infrastructure, reduced redundancy, increased reuse, improved collaboration, and optimized compute resources to power progress and business impact.
Modern Data Landscape – Key Evolution Drivers
|
Speed |
Scale | Cost-Effectiveness | Governance |
|
Faster time to insights with fewer resources |
More data sources, users, and uses, including self-serve |
Improved productivity and infrastructure utilization and optimization |
Governed access, activities, usage, and compliance |
|
Actionable Insights and Analytics – Relevant, Actionable, Impactful |
|||
AtScale Semantic Layer: Enabling Actionable Insights for Everyone
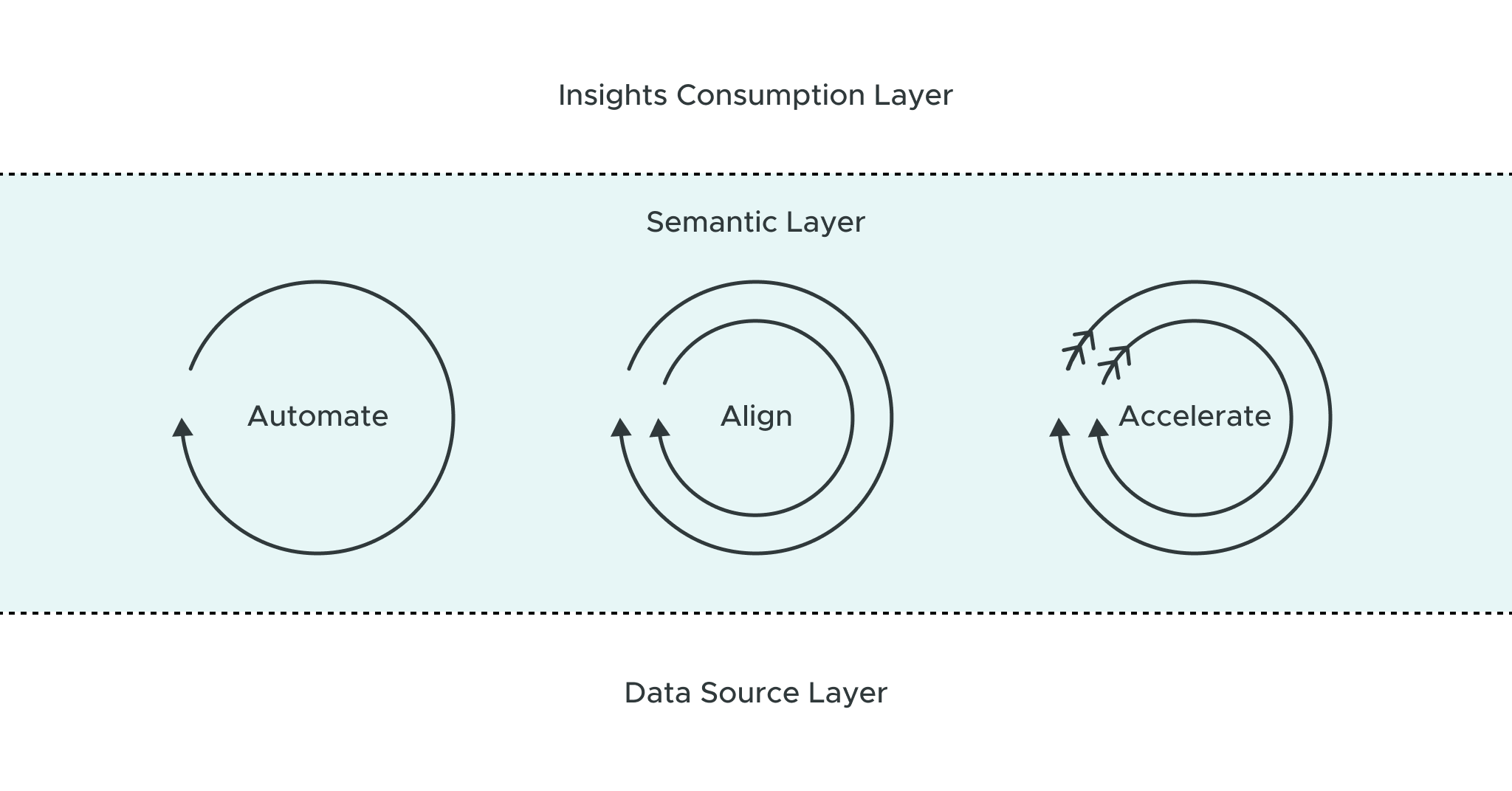
AtScale provides a semantic layer, which sits between the data source layer and the
insights consumption layer (e.g., AI, BI, and applications). The semantic layer converts data into actionable insights via:
- Automation (self-service data access, preparation, modeling, and publishing)
- Alignment (centralized data product management and governance with a single, consistent metric store)
- Acceleration (cloud analytics optimization, BI query speed optimization, multidimensional OLAP in the cloud, AI-based data connectors, and automated PDM tuning)
These capabilities support insights and analytics creators, enablers, and consumers without requiring data movement, coding, or waiting.
AtScale Semantic Layer
Enabling Actionable Insights for Everyone
Providing Automation + Alignment + Advancement
With No Data Movement, No Coding, and No Waiting
|
Automation |
Alignment | Advancement |
| Self-service data access, preparation, modeling, publishing for AI & BI | Centralized Data Product Management with Single Enterprise Metric Store |
10X Increase in Query Performance, Automated Tuning, Cloud OLAP |
SHARE
Whitepaper | Enterprise Semantics for Power BI