This post was written in collaboration with Swaroop Oggu, Solutions Architect at Databricks.
Dimensional analysis is an important tool for building analytics-oriented data products (e.g. interactive dashboards) based on data assets managed in a lakehouse. Historically, dimensional analysis has been tightly coupled with traditional OLAP tools like Microsoft SQL Server Analysis Services (SSAS). SSAS has been an industry workhorse for decades, with thousands of organizations relying on SSAS for mission-critical analytics that are most commonly distributed to users within Power BI dashboards or Excel pivot tables. Microsoft has updated the SSAS offering with cloud-hosted versions of the platform in the form of Azure Analysis Services and Power BI Premium.
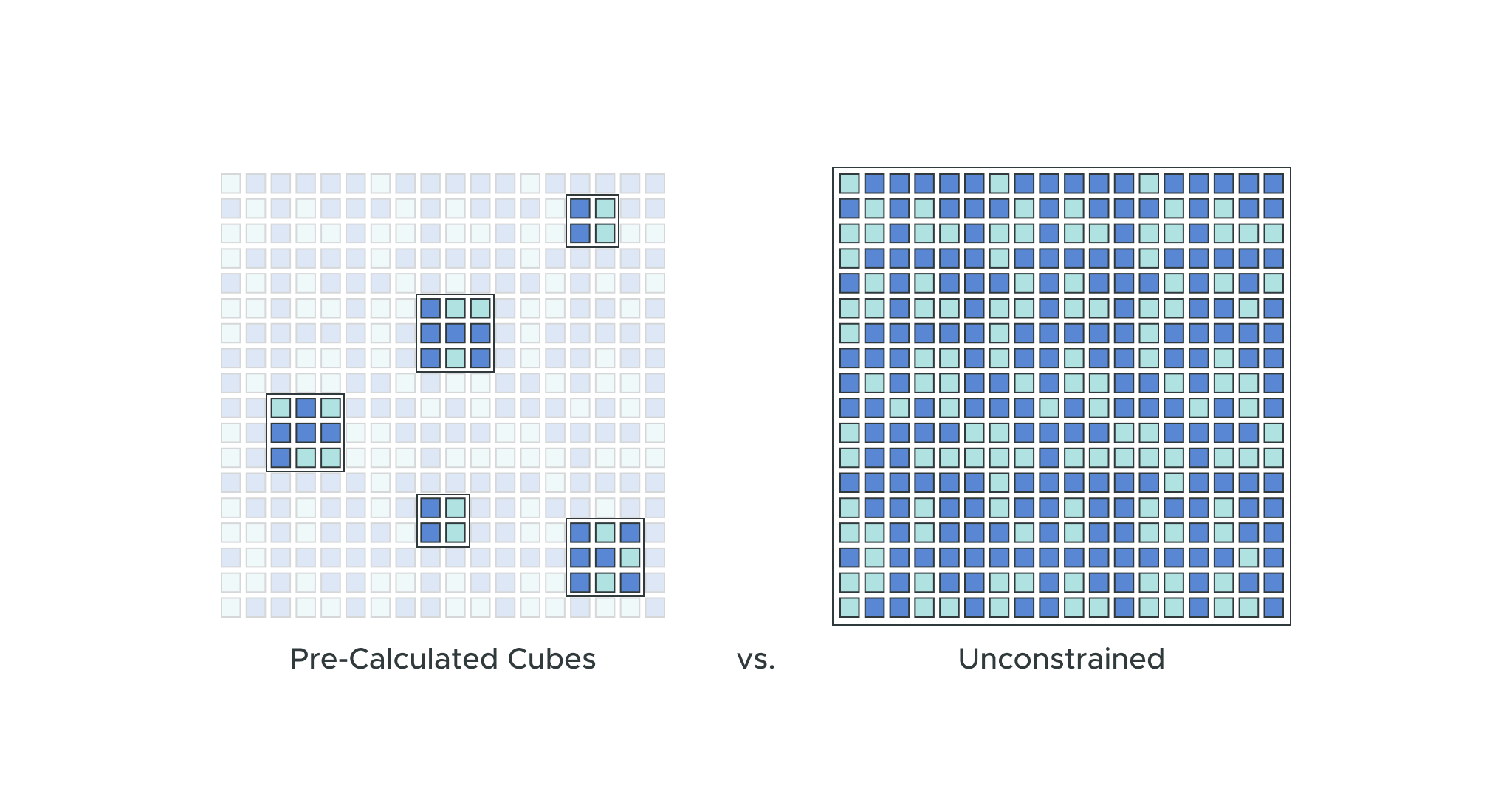
SSAS and its descendants offer a practical way to deliver a consistently high performance (i.e. speed-of-thought) and self-service analytics experience. Business users are able to easily cut and filter data at different levels of aggregation by navigating controls linked to a pre-calculated multidimensional cube. This lets data consumers use standard Excel and Power BI controls to slice and dice data using business concepts like time, region, product, and price without the need for technical expertise. This approach enables the extreme predictability that comes with constraining user queries to predefined dimensions and metrics.
The Practical Limitations of SSAS and Traditional OLAP
The fundamental limitation of traditional OLAP approaches like SSAS (and this holds true for more updated implementations of the SSAS technology within Microsoft’s Azure Analysis Services and Power BI Premium) is that they rely on pre-calculated cube data structures persisted outside of the lakehouse. Traditional OLAP approaches become more complicated, more expensive, and less practical as datasets scale. Pre-calculating cubes can take hours or even days to compute and build, which means they’re no longer feasible for large datasets.
In order to manage these limitations, organizations will build multiple cubes based on smaller subsets of raw data. This means that business analysts only get access to constrained views of data, limiting their ability to explore other relationships without requesting changes to their cubes. These disconnected data pipelines become very complex and cause delays in getting data consumers the views they need. This often results in shadow analytics programs with no central governance.

These SSAS cubes are physically disconnected from the centralized data platform. This means that business users will always be out of sync and working with stale data while the IT team has to maintain multiple data platforms and complex data pipelines.
Customers who use leading tools such as Tableau, Power BI, Qlik, and Looker want to report on the freshest, most complete data in the data lake — rather than only what exists in their data warehouse. With bifurcated architectures, data is first ETLed into lakes, and then again into warehouses, creating complexity, delays, and new failure modes.
When analytic data sets are drawn from multiple data platforms, the complexity of data pipelines increases as does the need for governance. The extra hops required for moving data across platforms creates a need for additional copies of the data and increased data processing costs. With disjointed systems, successful AI implementation becomes difficult. Actionable outcomes require data from multiple places, creating more data pathways and silos. Customers need to ensure data is synchronized and access controls are enforced the same way — these are just some of the operational issues that stem from having multiple data platforms.
With movement from a data lake to a data warehouse, common issues can occur. These may include:
A Lack of Support For Incremental Updates – With no built-in support for incremental updates, data refresh cycles depend on full loads and rebuilds. Customers need custom implementation with well-defined data partitioning and data modeling strategies to load the data needed for a specific date, which might not scale and adapt for constantly growing data. These measures are prerequisites that need to be applied across cubes to bring less data to the cubes and decrease process time.
Limited Elasticity – Scaling SSAS/AAS can only happen vertically, limiting the options and creating dependencies on pipeline SLAs.
Data Hops & Copies – Each data hop to build and refresh the SSAS cubes results in additional delays. As the need for more complex models arises, so will the need for additional data hops which thereby impacts the SLAs and freshness of data.
Data Context and Associated Actions – With multiple data platforms there is no way to implement contextual data actions based on data insights ( eg. updates to data / compliance related changes). A whole new process has to be built around multiple platforms to take necessary action.
Limited Support for Advanced Analytics – When moving the data from a data lake to a data warehouse, the access and ability to process complex data formats in high volumes for highly prescriptive analytics needs is lost. Advanced analytics use cases need systems that process large datasets and can provide critical business insights.
A Modern Approach to OLAP on the Databricks Lakehouse
The Databricks Lakehouse brings a new set of capabilities that, when combined with a semantic layer platform like AtScale, enable true speed of thought analytics without the constraints of a conventional OLAP approach.
With Databricks Lakehouse Platform Data Ingestion, data storage and data processing are under one roof, which enables going from ETL → BI → AI over a single governance model.
The core benefit of having the essential ETL capabilities in one platform include:
Data Ingestion
- No limits on data structure.
-
- Using a data lake as the single source of truth means that there are no limits to the kinds of data that can be ingested.
- Inherent support for structured as well as semi-structured and unstructured data.
- Full ACID support – no dedup/overwrites required and fault tolerance with automated scaling.
- Incrementally and efficiently processes new data files as they arrive in cloud storage with the help of Autoloader.
- Support for continuous and scheduled data ingestion across data formats.
- Change data capture and schema evolution support.
- Extensive partner ingestion tools support.
Data Storage
- Infinite storage capacity.
- With the unlimited availability of cloud-based object storage, organizations do not need to worry about running out of space.
- Low data gravity.
- The organization’s cloud object store keeps data in the format of choice.
- This arrangement has the lowest data gravity, meaning it is easiest to move from here to any other location or format.
- Delta Lake and open storage formats.
- Support for open and standardized storage formats (eg. Delta, Parquet, etc) so a variety of tools and engines can access the data directly and efficiently.
- Delta Lake provides transactional guarantees for high-quality, reliable data on the data lake with no vendor lock-in. Using Delta Lake on the Databricks Lakehouse allows you to get the best performance by utilizing Photon and built-in optimizations.
- Fulfill data versioning, reliability, and performance with Delta Lake
as the foundation.
Data Processing
- Mix batch and stream workloads.
- Building a system with Apache Spark means that the system benefits from the structured streaming capabilities of Apache Spark.
- Separation of compute and storage.
- The separation of computation and storage makes it easier to allocate resources elastically.
- A data lakehouse is the least expensive option for building a single source of truth. Organizations pay for compute only when needed.
- Leverage the best aspects of a data warehouse.
- Using a data warehouse as a query layer means that all of the advantages of a data warehouse can be leveraged for reads.
- High data throughput
- High data throughput refers to this architecture’s ability to handle a much higher volume of data per unit time.
The Databricks Lakehouse Platform lets customers run all SQL and BI applications at scale with up to 12x better price/performance over a unified governance model across clouds, open formats, and APIs, removing the need to manage multiple data platforms and multiple data hops to create a single source of truth. This allows for the use of all BI applications with tools of choice and no lock-in. The Databricks Lakehouse Platform empowers every analyst to access the latest data faster for downstream real-time analytics, and go effortlessly from BI to ML.
Databricks Lakehouse Platform enables customers to easily ingest, transform, and query all the data in-place to deliver real-time business insights faster. Built on open standards and APIs, the Lakehouse provides an open, simplified, and multi-cloud architecture that brings the best of data warehousing and data lakes together, and integrates with a rich ecosystem for maximum flexibility. With Databricks Lakehouse Platform customers get full visibility into query execution, with an in-depth breakdown at operation levels allowing teams to understand the performance characteristics of specific queries and optimize if need be.
With the help of Databricks serverless SQL, customers no longer need to make a tradeoff between availability and cost. Databricks SQL serverless removes the need to manage, configure, or scale cloud infrastructure on the Lakehouse, freeing up data teams for what they do best. Databricks serverless SQL provides instant, elastic SQL serverless compute decoupled from storage with the benefit of performance optimizations that can lower overall costs by an average of 40%. Serverless SQL provides the ability to scale up and scale down workloads instantly with out of the box support to adhoc data access needs required for bursty workloads. Databricks automatically determines instance types and configuration for the best price/performance — up to 12x better than traditional cloud data warehouses — and will automatically scale to provide concurrency without disruption, for high concurrency use cases.
Serverless SQL also removes the need of running the compute for long durations just to keep the data access available.
The Delta Storage layer is really what transforms a data lake to a Delta Lake. It runs on top of the cloud storage that holds all of your data. Keeping all of the data in files in object storage is the central design pattern that defines a data lake. On top of that, the structured transactional layer tracks and indexes those files, allowing users to use one platform for all data use cases: streaming, business intelligence, data science, and machine learning.
Lakehouses are enabled by a new system design: implementing similar data structures and data management features to those in a data warehouse, directly on the kind of low-cost storage used for data lakes. It’s a solution that mirrors what you would get if you were to redesign data warehouses in the modern world, now that low-cost, highly reliable storage solutions (in the form of object stores) are available.

With AtScale, Databricks users can support OLAP workloads directly on the Delta Lake while reducing the data engineering effort and infrastructure required. Rather than creating multiple physical cubes and additional serving layers outside the lakehouse for specific team needs, AtScale’s modern approach allows for more flexibility and eliminates additional infrastructure needs.
AtScale leverages three unique capabilities that enable a more modern approach to analytics acceleration and fully leverage the power of Databricks.
- Intelligent Aggregate Management – AtScale monitors user query patterns to identify what aggregates would be most beneficial to overall performance. This is a dynamic approach to creating aggregates on demand. Likewise, as aggregates are no longer used, they are released so as to not consume valuable storage resources.
- Dynamic Query Pushdown – AtScale translates logical queries into physical queries, optimized for the cloud data platform. By performing resource-intensive aggregations and transformations on Databricks, companies avoid unnecessary data movement.
- Graph-Based Query Planning – If an aggregate exists, the query may be rewritten to access the pre-calculated value. If it doesn’t exist, the query may execute against the raw data. If repeated queries against raw data occur, the planner may suggest the need for a new aggregate.
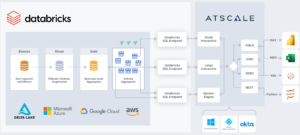
This radically simplifies the architecture needed to support these OLAP workloads and also ensures the experience for the Excel / Power BI users is not affected.
- AtScale supports native MDX connections to Excel using PivotTables or CUBE functions for a seamless, high-performance analytics experience on live Databricks Lakehouse data sets.
- AtScale is currently the only solution to provide a live DAX interface for Power BI. This live connection enables business users to visualize AtScale’s data models directly within the Power BI model canvas and execute high-performance “live” queries on the Databricks Lakehouse data without data extracts.
The AtScale platform makes this possible by emulating a SSAS endpoint through its implementation of the XMLA protocol and supporting the XML (Excel) and DAX (Power BI) dialects.
The Scale and Performance of the Semantic Lakehouse
In AtScale’s TPC-DS 10TB benchmark study for Databricks SQL, the AtScale platform demonstrated a 15x improvement in query speeds for up to 50 concurrent users. Not only can the AtScale platform obviate the need for a separate BI serving layer, the platform also improves user concurrency and scale by orders of magnitude, all while leaving the data in the Databricks Lakehouse.
Watch our panel discussion with Franco Patano, lead product specialist at Databricks for more information and to find out more about how these tools can help you to create an agile, scalable analytics platform.
If you have any questions regarding AtScale or how to modernize and migrate your Legacy SSAS estate to Databricks and AtScale — feel free to reach out to kieran.odriscoll@atscale.com or your Databricks representative.
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics