This is the last post in this blog series, The Semantics of the Semantic Layer, where I discuss the seven core capabilities of a semantic layer. In this blog, I will dive deeper into how a semantic layer should integrate with data platforms.
As a reminder, the following diagram shows the seven core capabilities for a semantic layer. This blog will focus on “Data Integration”, highlighted in red:

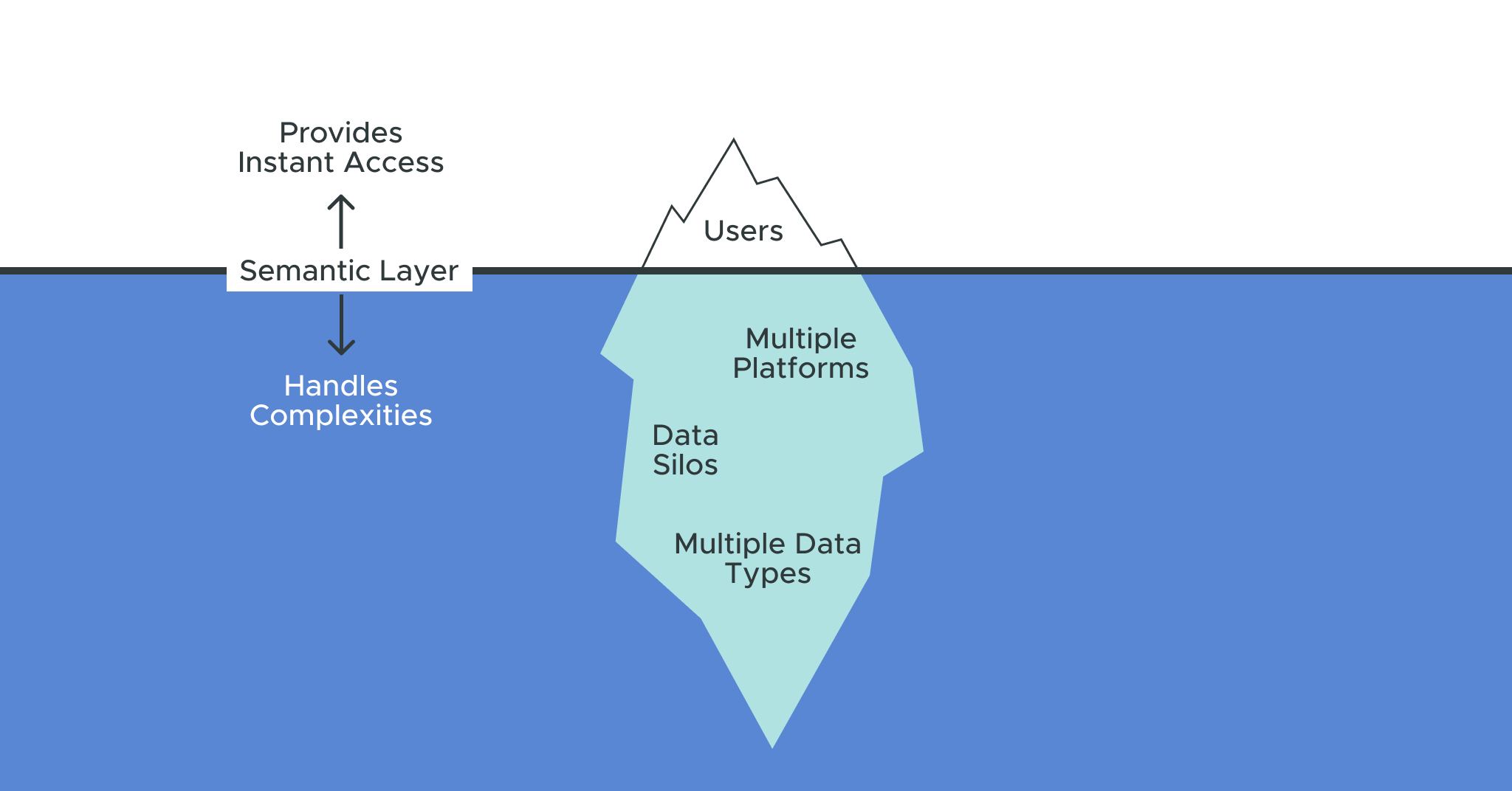
By hiding the format, location and complexity of data, a semantic layer provides a business-friendly view of data for everyone, not just data engineers and SQL jockeys. Delivering a logical view of data on a variety of data platforms has its challenges, though. In this post, we’ll drill down on some important considerations when evaluating a semantic layer’s ability to integrate disparate data sources.
Speaking Their Language
In addition to having various levels of support for SQL and SQL extensions, different data platforms have different performance characteristics and optimization controls. In order to avoid data movement and all its adverse effects, it’s imperative that the semantic layer generate platform-optimized queries and push down those queries to the underlying data platform. Lowest common denominator approaches that generate and execute simple, vanilla SQL and perform aggregations and calculations locally, just can’t scale and don’t allow customers to take advantage of platform-specific features.
A scalable semantic layer platform must integrate seamlessly with data platforms and must:
- Generate and execute multi-pass SQL and push down queries to the underlying data platform
- Leverage platform-specific optimizations, including partitioning, clustering and DDL hints
- Avoid a separate compute infrastructure to process query results
- Allow native SQL in calculations to leverage platform-specific and user-defined functions
With tight, platform-specific integrations, a semantic layer will generate optimized queries to deliver consistent performance and lower costs.
Key Takeaway: A semantic layer must work with a variety of data platforms equally well by supporting native platform dialects and optimizations.
Breaking Down Silos
It seems like just about every five years we see a new data platform technology or trend become all the
rage. If your organization has been around long enough, you probably have one of everything and a proliferation of cloud-based applications with your precious data locked behind their proprietary APIs. A semantic layer with data virtualization future-proofs your data platform technology choices by creating an abstraction layer between your data and the tools that interact with it. Besides hiding the complexity of each data platform and preventing vendor lock-in, a semantic layer minimizes or eliminates the cost of migration to new data platforms in the future by using data virtualization as its core mechanism for querying the underlying data.
A semantic layer with query federation goes even further to break down data silos than just virtualizing data access. As I discussed in my earlier blog, The Semantics of the Semantic Layer – Part 3, a semantic layer’s data model can blend data from multiple sources to create new, composite views of data for modeling complex business processes.
The illustration below shows how a semantic layer can blend data from multiple sources, including SaaS applications, third party data from exchanges and first party data:
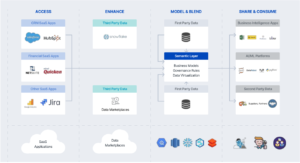
Key Takeaway: A semantic layer must support data blending across multiple data platforms and data sources and minimize data movement for federated queries by leveraging localized aggregates and query push down.
More Than Rows and Columns
In today’s cloud data platform world, a database table is no longer just made up of simple rows and columns. Modern data platforms now have advanced support for non-scalar data types like JSON and XML. Google BigQuery goes even further by allowing for nested and repeating fields, which effectively allows the embedding of tables within tables. For example, a customer table may take the form of:
-
id -
first_name -
last_name -
dob (date of birth)
-
addresses (a nested and repeated field)
-
addresses.status (current or previous)
-
addresses.address -
addresses.city -
addresses.state -
addresses.zip -
addresses.numberOfYears (years at the address)
-
It’s easy to see how powerful these constructs can be for compressing information and reducing table joins, something cloud data platforms are not good at. However, while these new constructs make data loading easier and querying faster, they add additional complexity for the user when writing queries. Besides having to understand these more complex table constructs, each data platform has its own proprietary syntax for unnesting these data types.
A semantic layer should hide this additional complexity from the end user and abstract away the dialect differences of each platform. In this way, data warehouse architects can take advantage of these powerful new “schema on read” design principles without creating an additional burden on their end users.
Key Takeaway: A semantic layer must support modern data platform features and constructs to support analytics on unstructured and semi-structured data.
Data Integration for Data Democratization
Besides serving as a metrics hub, a semantic layer must hide the complexity of the data stored in various data platforms. A well designed semantic layer will scale with your data growth (and your data platforms) by pushing down queries and leveraging each platform’s dialect and optimizations features. By eliminating data copies and data movement, a semantic layer can make data instantly accessible to everyone.
SHARE
Whitepaper | Enterprise Semantics for Power BI