
Just last week Cloudera released some impressive performance numbers showing how the Impala SQL-on-Hadoop engine scales to support concurrent query workloads. The Cloudera blog post confirms what we at AtScale have experienced with real-world customer installations – that Impala plus AtScale is a scalable solution for running concurrent, interactive business intelligence (BI) queries on Hadoop.
Impala has proven to be an excellent choice for supporting analytical SQL queries on large scale data sets. Several AtScale customers have chosen Impala as their SQL-on-Hadoop engine along with AtScale’s Dynamic Cube solution. With Impala, AtScale has proven that true interactive performance on a 50 billion row data set supporting multiple concurrent end-users is not only a possibility, but a reality.
In case you missed Cloudera’s post, here is a summary of the scale testing that the team at Cloudera performed:
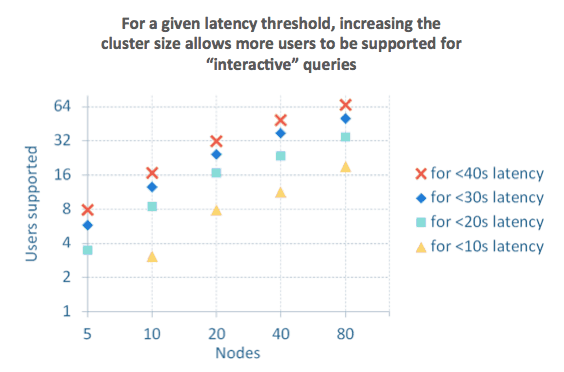
There are a few key observations that can be made from the chart above:
- Concurrency with Impala scales horizontally as more nodes are added to the cluster. This aspect of Impala is something that we rely on as part of AtScale’s architecture: instead of suffering from the architectural constraints of a traditional “Scale-Up” multi-dimensional OLAP server (like SQL Server Analysis Services), AtScale uses Hadoop to enabled a “Scale-Out” approach to OLAP. As data volumes or query volumes increase, the system can be augmented to support this growth simply by adding more nodes to the cluster.
- System throughput remains constant as concurrency increases. Another aspect of supporting Big Data analytics at scale is the need to support a range of query patterns, some of which may take more than a few seconds (or even a few minutes) to complete. While long-running queries may be occasionally unavoidable, it’s critical that they do complete, and do so without creating unacceptable throughput degradation for other queries on the same cluster. This critical aspect of Impala is even further enhanced by AtScale’s Adaptive Caching technology. By optimizing the data and incoming queries, AtScale reduces the overall resource demands on the Impala service, and greatly increases the number of concurrent queries that can be handled using the available throughout.
As the world’s first and only Hadoop-native Relational OLAP server, AtScale is excited about these latest results from Cloudera. AtScale relies extensively on SQL-on-Hadoop engines like Impala to support our scale-out approach to Business Intelligence. A quick refresher on what AtScale does:
- AtScale allows you to describe complex data residing in Hadoop as simple measures and dimensions, and presents a virtual OLAP cube semantic layer that BI tools (such as Tableau, Microsoft Excel, SAP Business Objects, Microstrategy, IBM Cognos, etc.) can connect to.
- AtScale intercepts and optimizes the complex MDX or SQL queries generated by the BI tools, and passes on optimized query plans to the chosen SQL-on-Hadoop engine for execution.
- Queries submitted to the AtScale engine are used to train AtScale’s Adaptive Cache, which is constantly evaluating the workload and creating a series of cache results to improve future query performance.
For AtScale to deliver the desired interactive experience that BI users have come to expect, the underlying SQL-on-Hadoop engine must deliver on the following criteria:
- Performs on Big Data: the SQL-on-Hadoop engine must be able to consistently analyze billions (or trillions) rows of data without errors and within an acceptable response time of 10s or 100s of seconds.
- Fast on Small Data: AtScale uses patent-pending Adaptive Caching technology to deliver interactive performance on known query patterns. It is important that the SQL-on-Hadoop engine returns results in under 1 second (or a few seconds at most) on small data sets (on the order of thousands or even millions of rows). This approach works extremely well with Impala, as shown below:
Table 1: Query Performance Increase Due to Aggregate Table Availability (Impala 2.2) - Stable for Many Users: AtScale is built to support concurrent connections from multiple BI clients, and as a result the underlying SQL-on-Hadoop engine must perform reliably under a concurrent workload of 10s or 100s of users.
Impala and AtScale together create a winning combination for supporting large scale Business Intelligence workloads on real-world use cases involving multiple concurrent users. Because AtScale’s Adaptive Cache vastly reduces query response time (and hence CPU utilization) the overall query volume and user concurrency that can be supported by the cluster increases exponentially, as shown below:
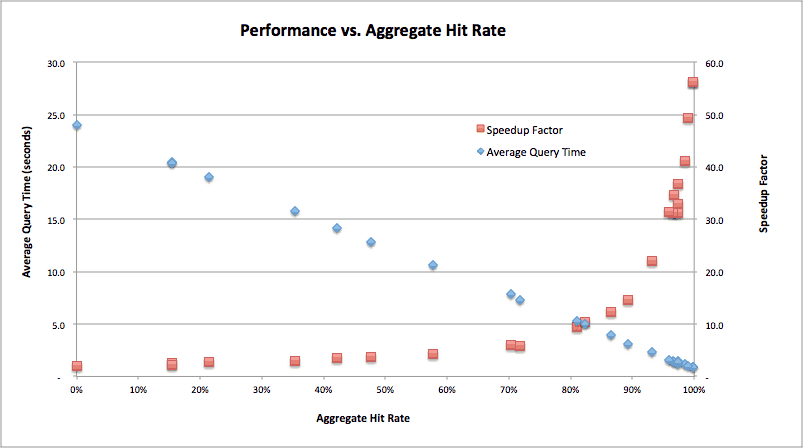
Table 2: Average Query Time Drops Significantly as Aggregate Utilization Increases
AtScale is excited to see the continued advancement of SQL-on-Hadoop engines like Impala. The ability to support concurrency in a scale-out environment combined with AtScale’s Hadoop-native architecture is a perfect combination for the rapidly growing BI-on-Hadoop segment.
To demo Atscale: Request a Demo
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics