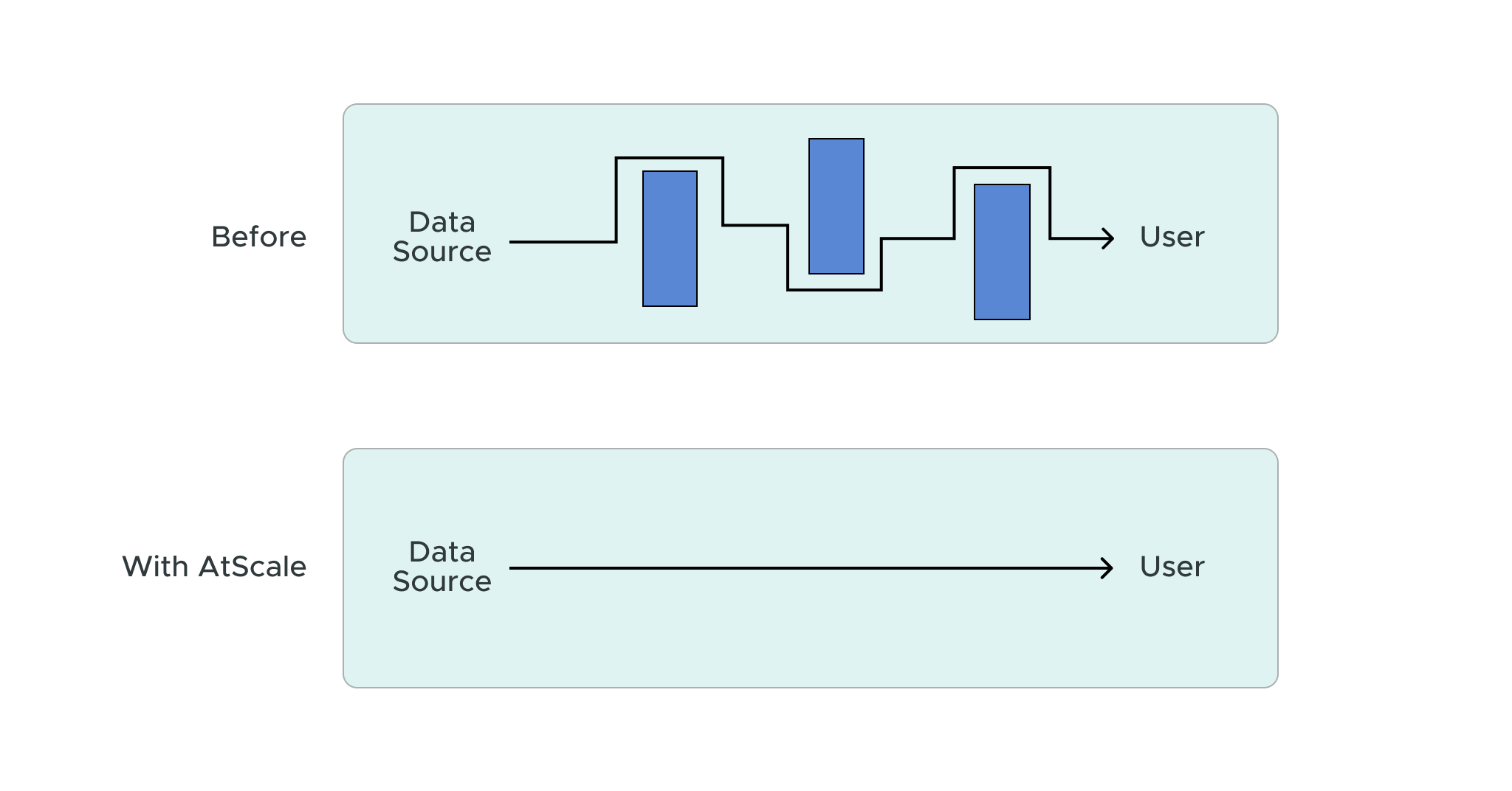
Our partnership with Snowflake has drastically sped up our customers’ data processing capabilities by eliminating the need for tedious data engineering tasks. By driving workloads directly to Snowflake, users can create accelerated time-to-prediction rates and a more efficient method to manage machine learning (ML) features — ultimately enhancing the feature engineering experience.
In a panel discussion with Simon Field, Technical Director at Snowflake, we took a deeper look into how combining the AtScale semantic layer with the Snowflake Data Cloud allows organizations to streamline data science workloads and the feature engineering process all in the cloud.
Here’s a summary of what we covered during our presentation and product demonstrations.
Snowflake’s Elastic Computing Engine
Simon Field started the presentation by briefly discussing the wide range of features of the Snowflake platform — acting as an all-in-one data engineering, data lake, data warehouse, data science, and sharing solution. Additionally, the platform can pull from a variety of applications (third-party or enterprise), web, and internet of things (IoT) data sources. It can also serve various data consumer use cases and run on the major public cloud platforms like Google, Amazon Web Services (AWS), and Azure.
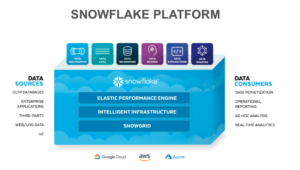
Snowflake System Overview
Field then helped us visualize the ML feature capabilities of Snowflake by showing them in relation to a typical data science workflow. He explained how the collection process is available in all forms (structured and semi-structured) through many data sharing options and external datasets. There’s also the ability to use process streaming technology to upload your data.
Once loaded, Snowflake has visualization and dashboarding functionality through its Snowsight interface and third-party business intelligence (BI) partners. It can then manage the feature engineering and transformation tasks (such as functional data engineering through Snowpark), and supports external functions through the application programming interface (API) for additional processing like scoring a model.
For the training and deployment stages, Snowflake works with an extensive ecosystem of partners and has a system with built-in support for popular technologies such as ODBC and Python. Finally, users can monitor their models through their BI tools or by using ML model management platforms that work with Snowflake, including DataRobot and Amazon SageMaker.
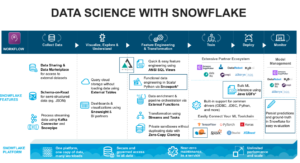
Snowflake Data Science Workflow
Making Predictions in Snowflake
After the platform overview, Field explained Snowflake’s external and Java functions for making predictions, which were demonstrated later in the presentation. For external functions, the data continuously travels to an externally hosted model using a REST API, which allows new data to be constantly collected and added to the model. Alternatively, Java user-defined functions (UDFs) are also available, which packages the model as a Java file — running it wherever the data lives.
Before passing the mic to me so that I could explain AtScale’s role in the workflow, Field discussed the interface he would be using during the demo called Snowpark. This native solution offers a new developer experience that lets users write and execute functional code directly in Snowflake using their preferred language and tools.
Ultimately, coding teams can efficiently complete data pipelines using familiar constructs and functions while accessing third-party data libraries. The entire premise is that all data operations stages are pushable into Snowflake — eliminating the need for other processing systems.
He also briefly touched on how developers can use Java functions in Snowflake to augment data using custom logic to manage ML scoring and access third-party libraries. The main benefit of this feature is that teams can build custom code in Snowflake with Java Virtual Machine (JVM) languages and popular libraries — treating the functionality as a built-in feature. This ensures data never leaves Snowflake and access permissions are controllable by system administrators.
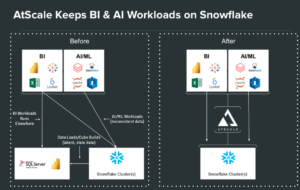
AtScale’s Semantic Layer Creates a Data Flywheel
My discussion focused on how the AtScale’s semantic layer presents a view of data that can be queried directly while pushing all compute down to Snowflake. Our solution presents consistent business metrics that BI and data science teams can access and consume using tools of their choice. It serves as the integration stage within enterprise data that simultaneously supports analytics, governance, and data security functions to accelerate end-to-end query performance — creating an efficient data flywheel.
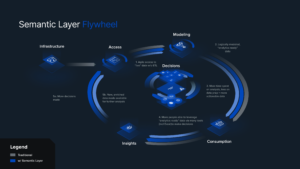
Semantic Layer Data Flywheel
AtScale bridges the data processing gap by acting as the central interface — connecting key performance indicators (KPIs), data dimensions, and hierarchical definitions that a BI team would use with a data science team’s predictive modeling tools and functions. The result: each primary function stays in sync, allowing teams to easily visualize how an enterprise’s data science initiatives are directly impacting the business.
Once the system is established, you can focus on pushing workloads downward directly into Snowflake. This includes BI workloads running somewhere else, cube builds, and AI and ML workloads. A consistent interface such as Snowflake to consume all of your data will eliminate the resources and effort required for data engineering, and reduce the risk of incorrect query results.
AtScale and Snowflake Alignment
Credit Card Fraud Detection Demo
While the beginning of the presentation covered the concepts and relationships between AtScale and Snowflake features, we spent the majority of time on a solution demonstration. In the use case example, Field and I went through each platform’s respective roles in streamlining the workflow stages of data collection, feature engineering, model training, and model deployment for predicting credit card fraud.
We started within AtScale using a credit card fraud dataset already uploaded to the system. Without any manual data engineering, we built out features and created and published models for consumption that are usable in many supported BI and analytics tools. In this example, we consumed it using a Python command line interface (CLI) — which created a single data extraction layer pulling information based on numeric and qualitative features.
After the feature engineering stage I showed, a data scientist would be able to train the model using ML tools like SciKit Learn and create a predictive model markup language (PMML) file. That file is deployable into Snowflake as a Java UDF using the Snowpark interface — demonstrated by Field to create predictions and calculate probabilities of fraud occurring.
Once Field defined the Scala function and added dependencies to the model, he was able to create the Snowflake UDF to test the model and apply it for analysis. Pulling new transaction data from AtScale that had not yet been used, he could apply the Java UDF to determine the probability that a transaction was fraudulent. Additionally, he could filter out specific cases of fraud based on the amount, certain terminals, dates, and all other data categories established earlier to provide key operational insights.
The AtScale Semantic Layer Streamlines Workloads and Feature Engineering with Snowflake
AtScale’s semantic layer enables users to model data, features, and relationships over Snowflake tables. Data engineers and scientists can then build out pipelines and execute models using a native data frame platform such as Snowpark. From there, models are storable through open model formats like PMML and deployable as Java UDF for faster code execution within Snowflake.
Be sure to watch our panel discussion with Simon Field on How to Streamline Data Science and Feature Creation Workflows in Snowflake to see the entire webinar.
SHARE
Power BI/Fabric Benchmarks