February 17, 2022
Using AtScale’s Semantic Layer with Data Science Use Cases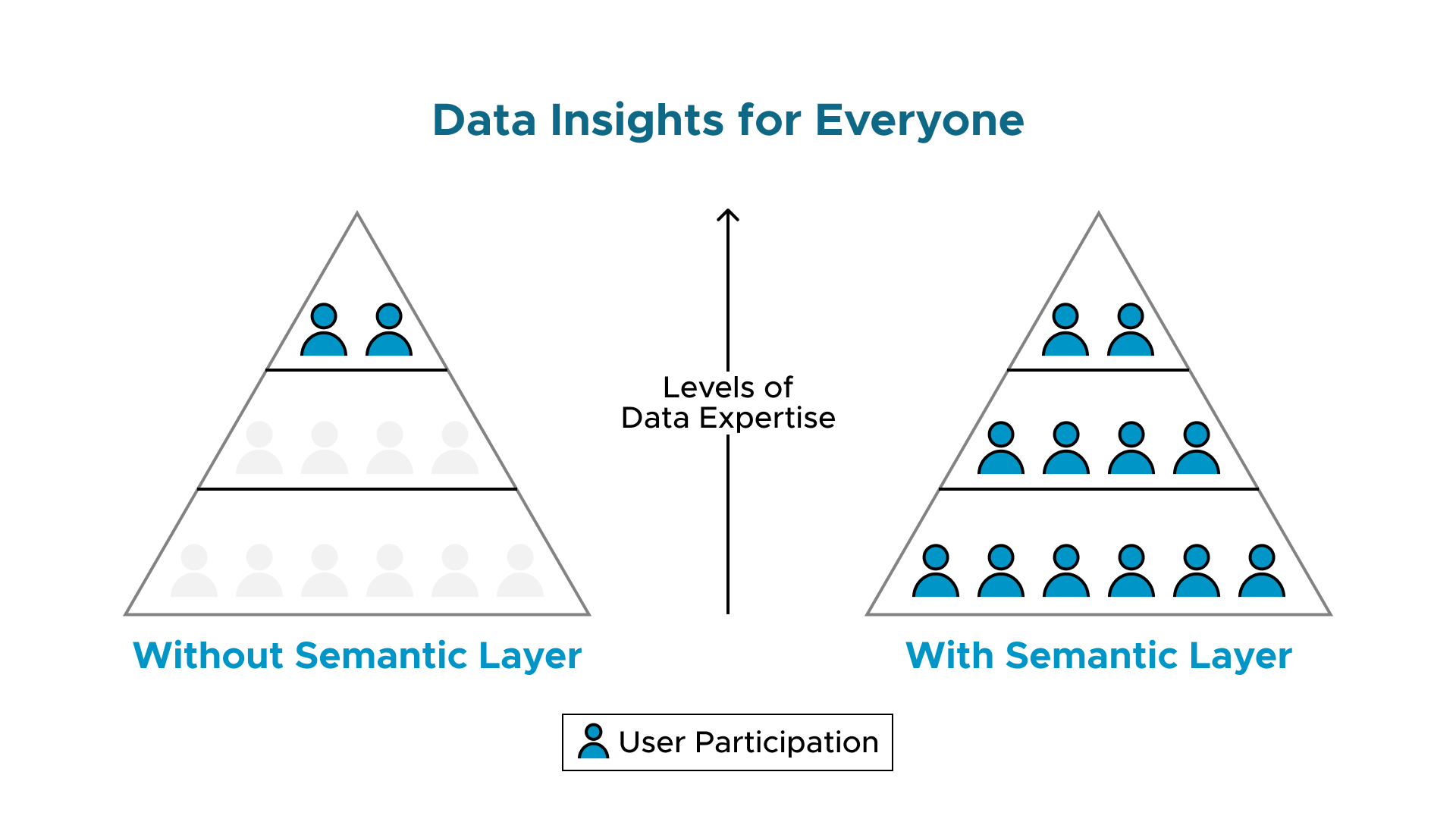
*Author’s Note
This article was originally posted as a LinkedIn article by Kirk Borne. Kirk Borne is the Chief Science Officer at Data Prime and has been an influential globally recognized leader in the data science space for 20 years. His areas of passion and focus include Big Data & Data Science, Artificial Intelligence (AI), and Astrophysics. Kirk is also the co-creator of the field of Astroinformatics. You can view the original article here.
What is a semantic layer? That’s a good question, but let’s first explain semantics. The way that I explained it to my data science students years ago was like this. In the early days of web search engines, those engines were primarily keyword search engines. If you knew the right keywords to search and if the content providers also used the same keywords on their website, then you could type the words into your favorite search engine and find the content you needed. So, I asked my students what results they would expect from such a search engine if I typed the following words into the search box: “How many cows are there in Texas?” My students were smart. They realized that the search results would probably not provide an answer to my question, but the results would simply list websites that included my words on the page or in the metadata tags: “Texas”, “Cows”, “How”, etc. Then, I explained to my students that a semantic-enabled search engine (with a semantic meta-layer, including ontologies and similar semantic tools) would be able to interpret my question’s meaning and then map that meaning to websites that can answer the question.
This was a good opening for my students to the wonderful world of semantics. I brought them deeper into the world by pointing out how much more effective and efficient the data professionals’ life would be if our data repositories had a similar semantic meta-layer. We would be able to go far beyond searching for correctly spelled column headings in databases or specific keywords in data documentation, to find the data we needed (assuming we even knew the correct labels, metatags, and keywords used by the dataset creators). We could search for data with common business terminology, regardless of the specific choice or spelling of the data descriptors in the dataset. Even more than that, we could easily start discovering and integrating, on-the-fly, data from totally different datasets that used different descriptors. For example, if I am searching for customer sales numbers, different datasets may label that “sales”, or “revenue”, or “customer_sales”, or “Cust_sales”, or any number of other such unique identifiers. What a nightmare that would be! But what a dream the semantic layer becomes!
When I was teaching those students so many years ago, the semantic layer itself was just a dream. Now it is a reality. We can now achieve the benefits, efficiencies, and data superhero powers that we previously could only imagine. But wait! There’s more.
Perhaps the greatest achievement of the semantic layer is to provide different data professionals with easy access to the data needed for their specific roles and tasks. The semantic layer is the representation of data that helps different business end-users discover and access the right data efficiently, effectively, and effortlessly using common business terms. The data scientists need to find the right data as inputs for their models — they also need a place to write-back the outputs of their models to the data repository for other users to access. The BI (business intelligence) analysts need to find the right data for their visualization packages, business questions, and decision support tools — they also need the outputs from the data scientists’ models, such as forecasts, alerts, classifications, and more. The semantic layer achieves this by mapping heterogeneously labeled data into familiar business terms, providing a unified, consolidated view of data across the enterprise.
The semantic layer delivers data insights discovery and usability across the whole enterprise, with each business user empowered to use the terminology and tools that are specific to their role. How data are stored, labeled, and meta-tagged in the data cloud is no longer a bottleneck to discovery and access. The decision-makers and data science modelers can fluidly share inputs and outputs with one another, to inform their role-specific tasks and improve their effectiveness. The semantic layer takes the user-specific results out of being a “one-off” solution on that user’s laptop to becoming an enterprise analytics accelerant, enabling business answer discovery at the speed of business questions.
Insights discovery for everyone is achieved. The semantic layer becomes the arbiter (multi-lingual data translator) for insights discovery between and among all business users of data, within the tools that they are already using. The data science team may be focused on feature importance metrics, feature engineering, predictive modeling, model explainability, and model monitoring. The BI team may be focused on KPIs, forecasts, trends, and decision-support insights. The data science team needs to know and to use that data which the BI team considers to be most important. The BI team needs to know and to use which trends, patterns, segments, and anomalies are being found in those data by the data science team. Sharing and integrating such important data streams has never been such a dream.
The semantic layer bridges the gaps between the data cloud, the decision-makers, and the data science modelers. The key results from the data science modelers can be written back to the semantic layer, to be sent directly to consumers of those results in the executive suite and on the BI team. Data scientists can focus on their tools; the BI users and executives can focus on their tools; and the data engineers can focus on their tools. The enterprise data science, analytics, and BI functions have never been so enterprisey. (Is “enterprisey” a word? I don’t know, but I’m sure you get my semantic meaning.)
That’s empowering. That’s data democratization. That’s insights democratization. That’s data fluency/literacy-building across the enterprise. That’s enterprise-wide agile curiosity, question-asking, hypothesizing, testing/experimenting, and continuous learning. That’s data insights for everyone.
Are you ready to learn more about how you can bring these advantages to your organization? Be sure to watch the AtScale webinar “How to Bridge Data Science and Business Intelligence” where I join a panel in a multi-industry discussion on how the AtScale semantic layer can help organizations make smarter data-driven decisions at scale. There will be several speakers, including me. I will be speaking about “Model Monitoring in the Enterprise — Filling the Gaps”, specifically focused on “Filling the Communication Gaps Between BI and Data Science Teams With a Semantic Data Layer.”
Look! Go here! Register to attend and view the webinar at https://bit.ly/3ySVIiu.

Note: This article was sponsored. The opinions expressed here are my own and do not represent the opinions of any other person, company, or entity.
Follow me on Twitter at @KirkDBorne
See what we are doing at AI startup DataPrime.ai
ANALYST REPORT