The use of AutoML products has increased drastically in the last few years as AI has become more widely applied in the modern data analytics stack. And there’s still potential for more growth in the years ahead; according to recent studies¹, the automated machine learning market is expected to grow at least 45% between 2020 and 2030.
AutoML’s premise is fantastic: democratize access to AI by abstracting away all of the intricacies that go into training, testing, and scoring models best suited to address a problem. But just like other AI initiatives, the application of AutoML should be carefully scoped. ML model builders — namely the data scientist and ML engineer — must take an active role not just as producers, but as strategic advisors for the implications of the model to the business.
In our second AI Innovation Council meeting, we discussed the growing presence and role of AutoML as a tool used by businesses and data science teams to accelerate AI initiatives. In this discussion, I was joined by:
- Dr. Amita Kapoor, Head of Data Science at Diggity.io
- Brian Prascak, Co-Founder, Chief Insights Officer at Naratav
- Jett Oristaglio, Founder at EthosAI
- Haley Hataway, Head of Data Strategy at Mentra
- Miles Adkins, Senior Partner Sales Engineer – AI/ML at Snowflake
We discussed a variety of topics including:
- Who and for what use-cases are AutoML products best suited for?
- Will data scientists and the business ever truly trust the use of these models? Will they replace the role of a data scientist?
- Are there new opportunities or exciting advancements that will further empower AutoML capabilities or enhance trust in these platforms?
Key Takeaways About AutoML
Generally, AutoML can provide a lot of value to businesses and data science teams who are looking to start or scale ML initiatives; automating the build process and removing potential pitfalls that come from complicated model crafting techniques such as feature engineering and hyperparameter allows the data scientist to focus on more strategic tasks in the data science workflow. Improving speed, introducing consistency in model building, and promoting model performance assessment methods (e.g. scoring) reduces the barrier to entry for ML and allows for expedited experimentation needed at the start of ML initiatives. We also learned that AutoML introduces great new operational efficiencies in regards to standards of reusability and governance as data science and ML platform teams look to institute MLOps and scale ML initiatives.
However, these products come with limitations too, namely: a lack of support for data wrangling, drift and model observability, and increased perception of the black box of AI means that use of these tools can actually impede, rather than accelerate, ML initiatives.
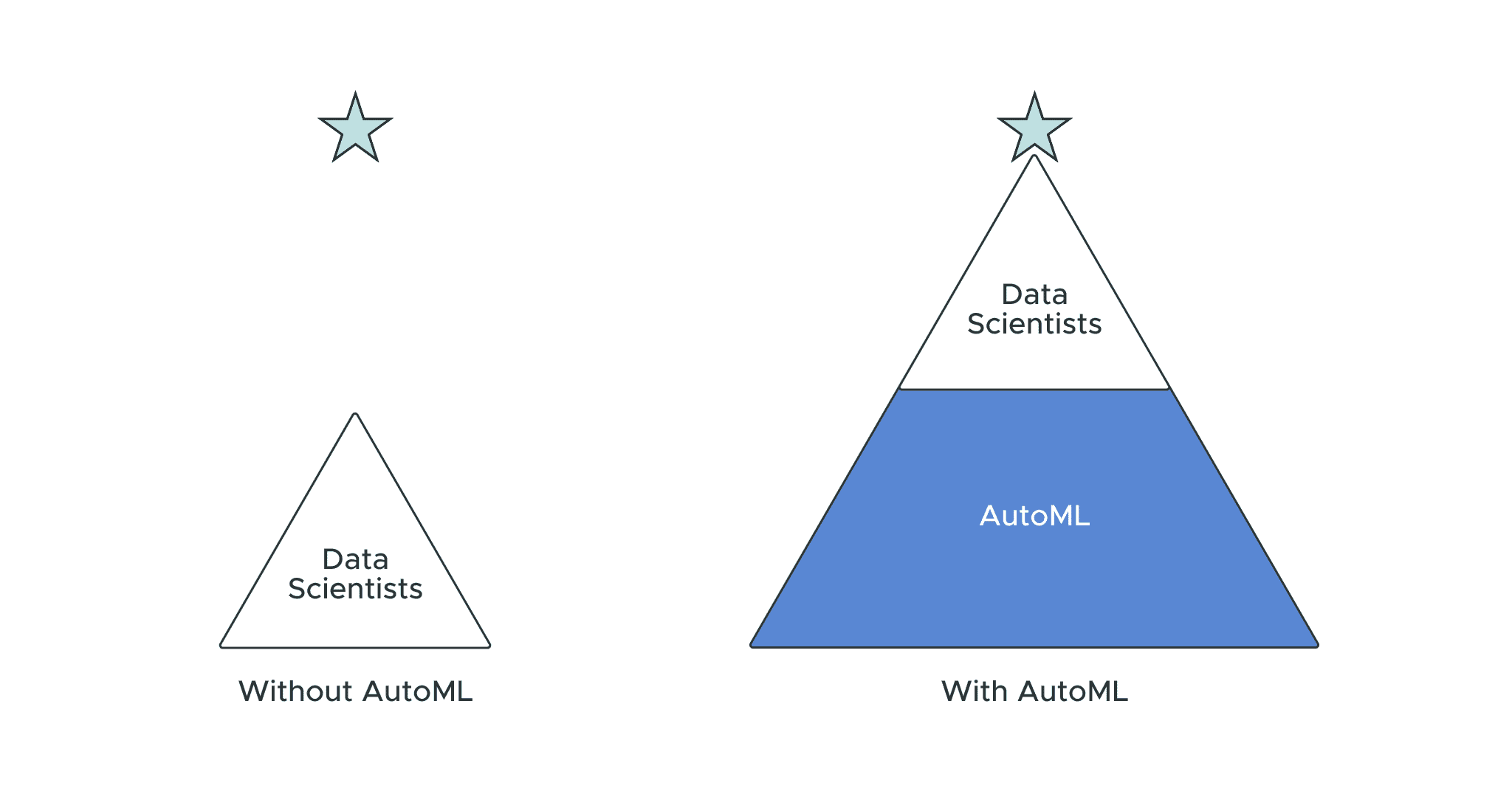
AutoML Can Lower the Barrier to Entry for Creating ML and Consuming ML Output
Providing extensible frameworks for low code/no-code, and very straightforward input/output paradigms, AutoML provides an easy access point to rapidly train ML models that can be exported, tuned, and scaled.
“[AutoML] is useful when you need to brute force or tackle one very high-value problem; it’s used in that way in more of an exploratory fashion…you can see what sticks and send in the team to optimize around that.”
Jett Oristaglio
Because AutoML introduces new, easier access to ML, distributed teams can more easily capture and start to understand the implications of ML output to help solve key business challenges.
Teams with no knowledge of AI can use AutoML to provide insight into how a problem could be solved with ML techniques, and render trained models scored to end users to then determine how they want to proceed.
Data science teams can also leverage AutoML to rapidly experiment and establish model performance baselines a key insight from our last council meeting, about Ops for MLOps) as a crucial first step to determining the role of the ML model in addressing a business problem. This is particularly useful for teams who are growing, and may not have the runway or resources to experiment for a long time.
“Running a small team, not being able to necessarily hire five or ten data scientists, AutoML lowers the barrier to entry with AI very quickly.”
Haley Hataway
The Best AutoML Tools Augment the Work of Data Scientists in the ML workflow (It Doesn’t Replace Them)
Automation can be intimidating; it can pose threats to jobs, businesses, and even entire industries. As a result, the positioning of automated tools is often just as important as the application of the technology itself. This was one of the pitfalls of AutoML products in its early commercialization; recognizing the complicated tasks associated with training ML models, AutoML was positioned as a way to remove the labor overhead tied to data science teams.
“You can’t get humans out of the loop. That’s an error that a lot of AutoML companies have made in the past. There are kinds of errors that happen in data science that only humans can understand because they understand the context of the data, the way it was collected, and how it should be used for the ML model.”
Jett Oristaglio
The fact of the matter is that humans maintain critical roles in the oversight and management of ML model application; they still maintain the context of the problem, data, and the appropriate application of ML models to address it based on their experience.
“These [AutoML] tools are helpful, but to a certain level, and you cannot remove the human from the picture altogether. A human is needed in the loop always…Lots of companies are out there focusing on AutoML to lower that barrier to entry, but they cannot replace the 10 years experience.”
Amita Kapoor
In many cases, the best AutoML tools provide a mechanism to remove the time-intensive activities from the ML model build process, and as a result, allows the data scientist to focus on scaling, tuning, and the strategic implication and implementation of the model in a production environment.
“AutoML automates away a lot of the technical grunt work and brings a lot of attention to what actually drives value in this process.”
Jett Oristaglio
“AutoML is something that lowers the barrier to entry, it doesn’t replace data scientists, but allows you to not focus so much on the little details. Learn conceptually and then take it to the next level… AutoML is not replacing data scientists or removing the need to understand how to do important things like feature engineering, but allowing the data scientist to focus on the more complex issues versus the tried and true that takes a lot of time.”
Haley Hataway
AutoML is a Catalyst to Establish Good Practices for MLOps and Ethical AI
As businesses look to grow their analytics capabilities with ML models, establishing standards for operations of models at build time is crucial to create consistent development patterns that will allow ML initiatives to scale and head off potential bias that may emerge either from data or influence in model construction.
AutoML provides a stepping stone to establish a consistent paradigm for initial model training and selection.
“The process is where the issue is… not just getting it done quicker, but doing it in a way that is consistent, auditable, and repeatable.”
Brian Prascak
“What’s valuable about AutoML is that it creates a reproducible standard that is hard to do with humans; there are a lot of weird, tricky little ways that you can screw up an ML project… Humans will overlook intuitive problems AutoML can solve for, but can also solve for some of its pitfalls; AutoML will not be able to understand the change in difference of data based on new circumstances.”
Jett Oristaglio
Platforms training these models will do so based on input data and config parameters determined by end users. As a result, with clearly defined context and objectives, AutoML can be used in combination with other key MLOps tools to help institute ethical AI practices.
AutoML can also uncover and promote best practices to mitigate bias, and promote attention towards the implications of the model output for end consumers.
“From an optics perspective, it can be seen of as more of a black box; there’s a bit of a negative stigma about automating things…but at the same time that standardization makes the compliance discussions much easier, it’s built-in explainability in a lot of ways.”
Haley Hataway
“AutoML is a stepping stone towards really robust, ethical AI.”
Jett Oristaglio
A Semantic Layer Simplifies Model Pipelines and Provides Context for ML-Driven Strategic Decisions
It’s a well-known problem: data scientists are often not presented with a full spectrum of data to create performant ML models (or have compute/RAM constraints).. The implication of these limitations force data scientists to use extracts or copies of data (introducing compliance nightmares) to train ML models. As a result, ML model pipelines become divergent across experimentation, training, inference, and production.
Additionally, data scientists often have to spend lots of time with other stakeholders trying to understand the context for structure, definition, and metrics used by business analyst teams to analyze and set the stage for problems to be solved with ML. Models have to be trained using metrics defined by the business in order to derive the insights the business wants to make informed strategic decisions.
Data scientists need access to a semantic layer in order to understand the nature of the data structure, metrics, or independent variable definitions they’ll use to train and perform inference on.
“The value and art of feature engineering comes from the context of the data and how it’s being used in the real world; the more the data scientist are focused on the business strategy and how their models are actually driving value in the world and less about the shiny new tools they’re using, the greater their contribution will be to the initiative.”
Jett Oristaglio
“It always helps to have some sort of domain expertise to apply to ML, and if the data scientists don’t, they certainly should be exposed to it.”
Brian Prascak
Data Scientists Accelerate Technological and Sociological Advancement of the Data Mesh
Data scientists bring a unique skillset to the table in an analytics organization; they have the requisite analytical and computational prowess and a methodological approach to creating models to solve key business challenges.
As companies look to embrace domain-driven data platform strategies to drive more tailored self-service analytics through data mesh² constructs, federated team management models empower data scientists to more effectively tailor ML and other automation solutions. Rather than traditionally operating in silos, an embedded team structure allows data scientists a more direct line to business challenges and a seat at the table to optimize the efficacy and understanding of models being moved to production.
Data scientists can help bridge the gap between AI and BI understanding, but need to be continuously involved to help provide the context and handoff to teams responsible for the scaling, maintenance, and analysis of model performance.
“Data scientists should be a part of the discussion with executives about discovered bias — how bias affects the decisions the model is making and how to address it — in the same way that they may be talking about how to predict profit of the model.”
Jett Oristaglio
Data scientists can’t just be looked at as individual contributor laborers to creating models. Rather, they must be viewed as strategic influencers for the decision-makers in the business.
“Data scientists are generalists with an amazing skill set; they have a combination of business, analytical, technical, and conceptual [skills]…Data scientist is a strategic partner who deserves to be at the table when there are conversations that involve business direction and how to get the most value out of it up front vs. a drive through of ‘give me these three models, stat.’”
Brian Prascak
“Separating out product and data science teams creates huge issues from the get-go; you can’t really just have a data science team siloed away hands on keyboards. They need to be involved in the discussion. It’s going to be essential for data scientists to have the communication skills, and the understanding of different perspectives of the business, so they can get the risks across in a way that makes sense to people who aren’t necessarily machine learning experts.
Haley Hataway
Stay tuned for upcoming meetings and intellectual capital from this team. If you’d like to participate in the dialog, don’t hesitate to reach out directly, zach.eslami@atscale.com.
Visit our blog for more AutoML resources.
- “14.83 Billion Automated Machine Learning Learning (AutoML) Markets,” Business Wire, February 2022.
- “What is a Data Mesh – and How Not to Mesh it Up,” Monte Carlo, August 2022.
SHARE
2026 State of the Semantic Layer