September 16, 2020
Google BigQuery Benchmark Results: A Closer Look
Have you either chosen Google BigQuery as your cloud data warehouse platform or you are considering doing so? The good news is that Google BigQuery is a great data warehouse platform that I highly recommend. However, there are some major gotchas you need to consider before jumping in with both feet. It comes back to what my dad always taught me as a kid. He would say, “Dave, there’s no free lunch”. Of course, he was right. When it comes to BigQuery, there’s no “free lunch” on solving your query performance issues, user concurrency challenges or magically reducing your infrastructure costs. In this post, I’ll lay out some of the BigQuery potholes and explain how AtScale can help you avoid them.
BigQuery Is Fast, But Not Fast Enough For BI
When it comes to fast full table scans, Google BigQuery is at the top of its class. You can scan billions of rows in seconds. However, when it comes to joining tables, things don’t look quite as good. Like most cloud data warehouses, Google BigQuery is optimized for reading a single large, flat table, not joining multiple tables using keys. Of course, business intelligence (BI) applications require star schemas and table joins to aggregate data on the fly. I’ve witnessed many customers who mistakenly thought BigQuery would perform at least as well as Teradata or Oracle. There are several approaches to mitigating this problem but they all require manual data engineering to either create aggregates or flatten your tables to make them work for BI.
AtScale’s Autonomous Data Engineering™ and Acceleration Structures solve this problem by automatically tuning BiQuery workloads based on user query behavior without manual data engineering and tuning. In the chart below, see how AtScale improves BigQuery performance by 20 times in a TPC-DS 10TB benchmark.
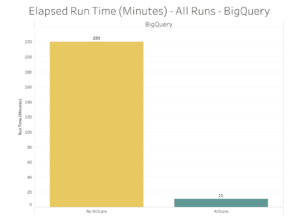
Source: AtScale Cloud Data Warehouse Benchmark Study
BigQuery Doesn’t Mean Unlimited Concurrency
Typically, the longer queries run, the fewer users can run queries during that time, or, each query runs longer. While Google BigQuery does a great job at lifting the threshold for query concurrency and mitigating queuing, it doesn’t have a magic wand to make concurrent workloads cost free. Whether you’re on a “pay as you go” consumption plan or a fixed rate plan, Google BigQuery allocates a fixed number of compute “slots” to your workloads. To increase user concurrency, the trick is to make each query run faster so other queries can run without contention.
AtScale improves user concurrency by re-writing queries automatically to avoid repetitive table scans. AtScale’s Acceleration Structures behave like automatic materialized views, making queries run orders of magnitude faster which results in dramatically improved user concurrency.
In the chart below, see how AtScale can serve 50 concurrent users without degrading performance a bit. In contrast, notice how Google BigQuery without AtScale scales linearly with additional users in terms of query run time.
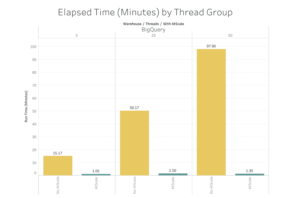
Source: AtScale Cloud Data Warehouse Benchmark Study
BigQuery Is Not Cheap
If queries run longer, they are typically scanning more data. If you’re on a consumption-based pricing plan ($5/TB read), that can get expensive fast. All it takes is a few errant queries to double or triple your monthly bill. I experienced that myself when running the benchmark for Google BigQuery. My testing resulted in a $24,000 bill for the month – my CFO was not happy! On a fixed rate pricing plan ($10,000/500 slots per month), you won’t have to worry about unpredictable bills but you still need to deal with unpredictable performance and user concurrency. The more data queries read and the longer they take forces you to purchase more slots for the equivalent workload which, again, gets costly fast.
Just as AtScale improves user concurrency with faster queries and shorter run times, it does the same for reducing cost. By rewriting queries to avoid table scans, AtScale automatically cuts costs on a consumption-based pricing model by reading less data (fewer TBs read). For the fixed rate pricing model, AtScale allows for larger workloads and more concurrent users without the need to add more slots, again, lowering costs substantially.
In the following video, see how AtScale reduces the cost of a TPC-DS query by 180x (6 minute video):
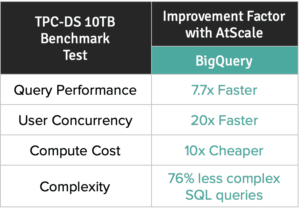
I know this is a lot to consider. Lucky for you, we’ve spent some serious time and money to test all the major cloud data warehouses using the industry standard TPC-DS benchmark methodology. If you have some extra bucks and time, you can reproduce these results yourself using our public GitHub library or you can download the reports on our website here.
BENCHMARK REPORTS