October 24, 2019
How to Become Truly Data-Driven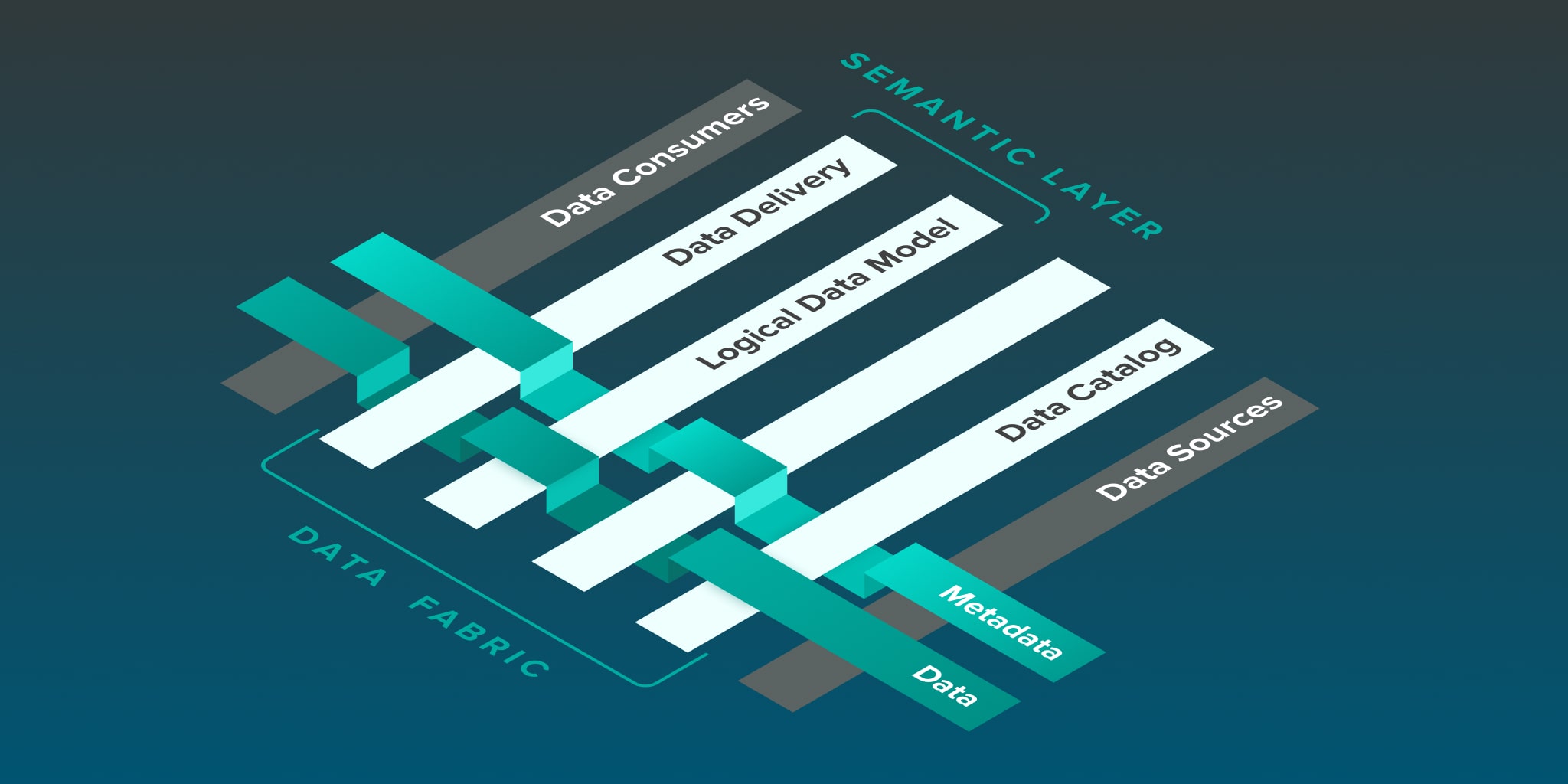
An Adaptive Analytics Fabric answers enterprise demand for agile, data-centric architectures for advanced analytics.
Some of the top trends that data and analytics leaders need to address to be relevant and impactful in advancing their critical business priorities have been outlined in Gartner’s latest global market study. Gartner predicts these trends will have significant disruptive potential over the next three to five years. Specifically, the ability to enable frictionless access and sharing of data in a distributed environment (called a data fabric) will enable companies to overcome the challenges that data silos present.
“The size, complexity, and distributed nature of data, speed of action and the continuous intelligence required by digital business means that rigid and centralized architectures and tools break down. The continued survival of any business will depend upon an agile, data-centric architecture that responds to the constant rate of change.”
—Donald Feinberg, Vice President at Gartner
With increasingly distributed, dynamic and diverse data (440x more data by 2020 from IDC Worldwide Big Data and Business Analytics Market Through 2022), AtScale’s Adaptive Analytics Fabric moves beyond a traditional static approach to data infrastructure management and automates analytical workloads while unifying data sources while working with existing data applications and platforms. Citizen data analysts need platforms that are both operational in scale and flexible enough to support the sophistication of their analyses used in deriving deep meaning and predictive insights from data.
WHY A DATA FABRIC?
Data fabric enables frictionless access and sharing of data in a distributed data environment. It enables a single and consistent data management framework, which allows seamless data access and processing by design across otherwise siloed storage.
Data fabric like AtScale, as defined by Gartner, adds more definition to the model and connects software and systems without adding the complexity of another data platform.
In short, a data fabric is a combination of architecture and technology that is designed to ease the complexities of managing many different kinds of data, using multiple database management systems, and deployed across a variety of platforms.
To extract value from data, it must be easy to explore, analyze and understand. After all, the ultimate goal of using data is making decisions from it. Business intelligence and data science in the hands of citizen data analysts does just that. But the volume of data requires a more holistic approach to helping companies innovate faster while addressing the increasing complexity and scarcity required of data engineering resources.
Today’s global enterprise organization has data deployed on-premises and in multiple cloud environments. The types of data (outside of the immense volume of data) include data in relational databases, flat files, data lakes, data stores, and more. Managing data workloads spans technologies from batch ETL to stream processing. The sheer number of applications, platforms and data types makes it difficult (and sometimes impossible) to manage the processing, access, security, and integration across multiple platforms. A data fabric consolidates data management into one environment, automatically managing disparate data sources and technologies in both on-premises and cloud environments. It does the work of hard to hire and retain data engineers.
The pace and diversity of change are increasing faster than is humanly possible to manage. As new technologies, new kinds of data and new platforms are introduced, the data fabric acts as a unifier—doing the translation and integration that’s needed and eliminating the manual methods. Because it is centralized and policy-based, it’s possible to govern and protect in a self-service deployment.
Even more critical, a data fabric only moves data if it’s required (e.g. moving from a legacy data warehouse to the cloud). Remember, changing data management methods for each new technology is not sustainable, is difficult to maintain and is disruptive to the business. The need for speed is the competitive differentiator for global enterprises. A data fabric can serve to minimize disruption by creating a highly adaptable data management environment that automatically adjusts to changing technology.
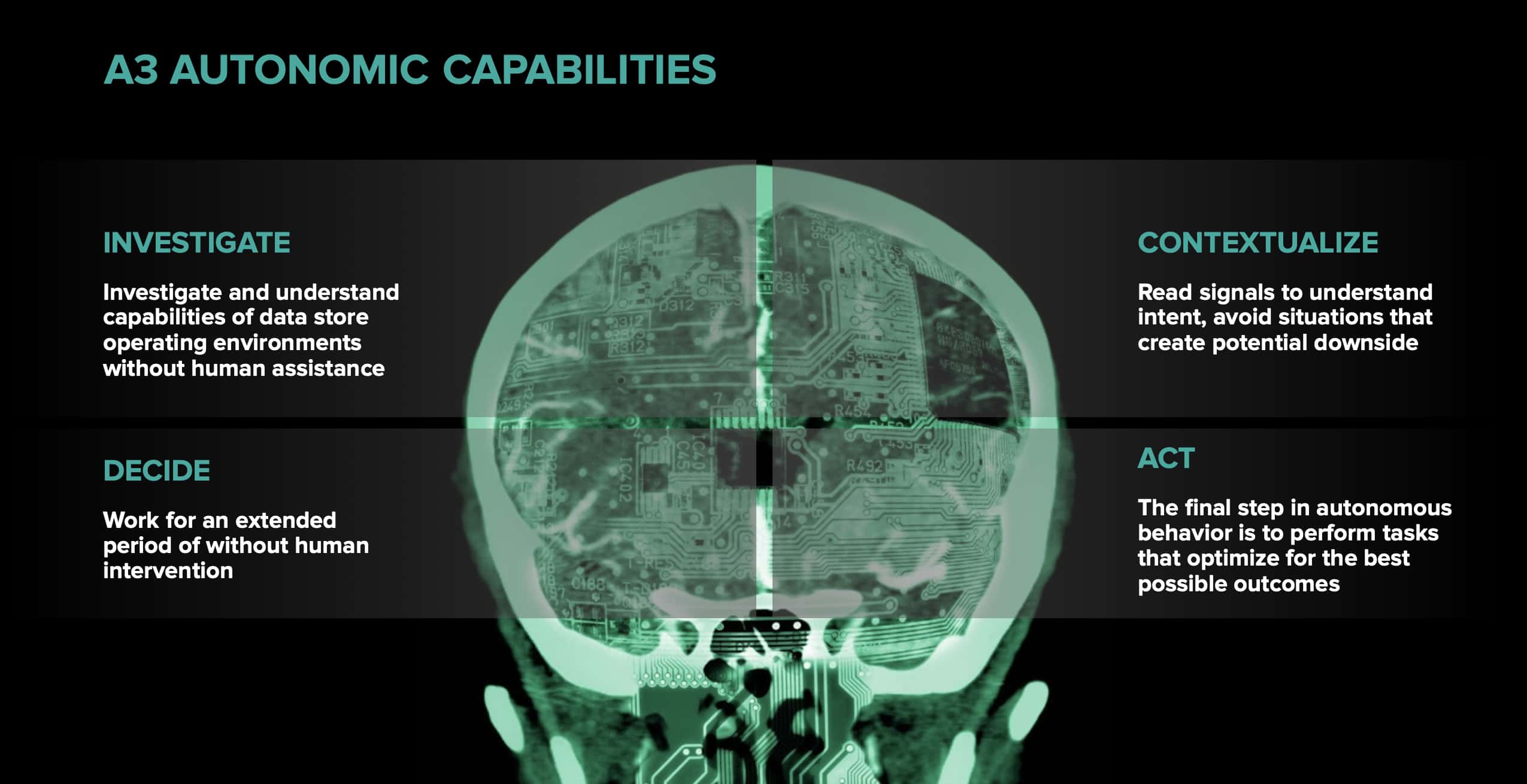
The evolution of the data fabric concept is the use of ‘autonomic’ approaches to explain how modern systems employ AI/ML driven automation to adapt based on how they interface with data platforms and consumer behaviors. With AtScale’s A3 platform, Machine Learning (ML) delivers its autonomous capabilities with the goal to reduce human labor (or chores). The benefits deliver agile and governed analytics to the enterprise just-in-time, shifting resources from managing trillions of rows of data—to analyzing it.
A true data fabric solution should have the following capabilities:
- Autonomous data engineering: Just-in-time query optimization for speed and usage consumption that can anticipate the needs of the data consumer in a single framework, reducing the complexity of data management and adapting to the needs of the data consumer.
- Unified data semantics: A workplace for all data for consumers to define business meaning and get a single-source-of-truth (SSOT) point regardless of structure, database technology, and deployment platform for a cohesive analytics experience.
- Centralized data security & governance: A centralized security policy to decentralize access using the tenets of Zero Trust that are applied consistently across the infrastructure for all data whether in cloud, multi-cloud, hybrid, or on-premises deployments.
- Data management visibility: The ability to measure data responsiveness, availability, reliability, and risk in a centralized workspace.
- Agnostic to platform and application: An ability to quickly integrate with data platform or BI/ML application for freedom of choice for data managers and consumers alike.
- Future-proofs infrastructure: Reduce the disruption of new technologies and data types while modernizing legacy systems to maximize investments. New infrastructure deployments are integrated without impact to existing infrastructure and deployments.
- No need for data movement: Intelligent data virtualization creates a single representation of data from multiple, disparate sources without having to copy or move the data.
AtScale has data fabric in its core providing a single, secured and governed workspace for distributed data that powers today’s more aggressive advanced analytics initiatives.
NEW BOOK